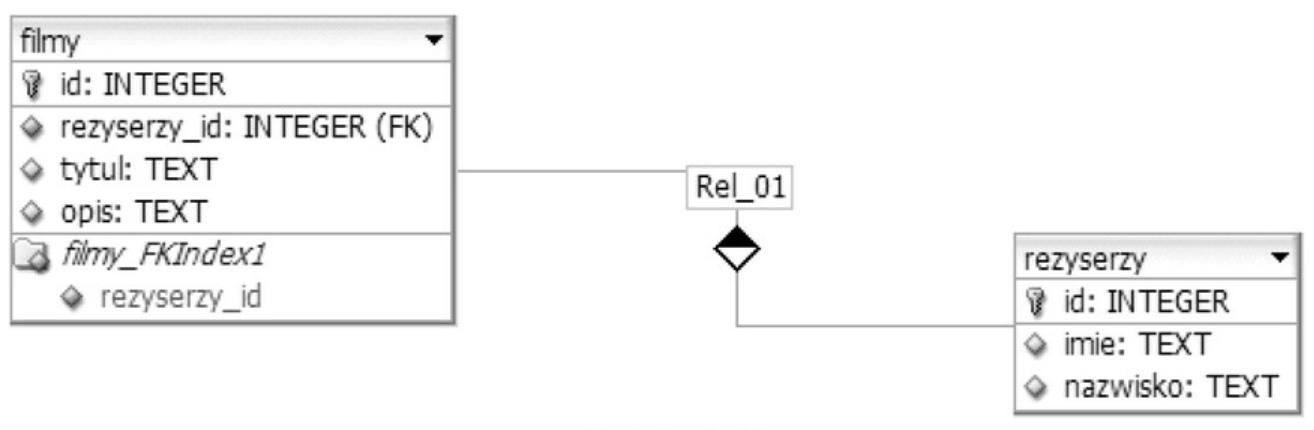
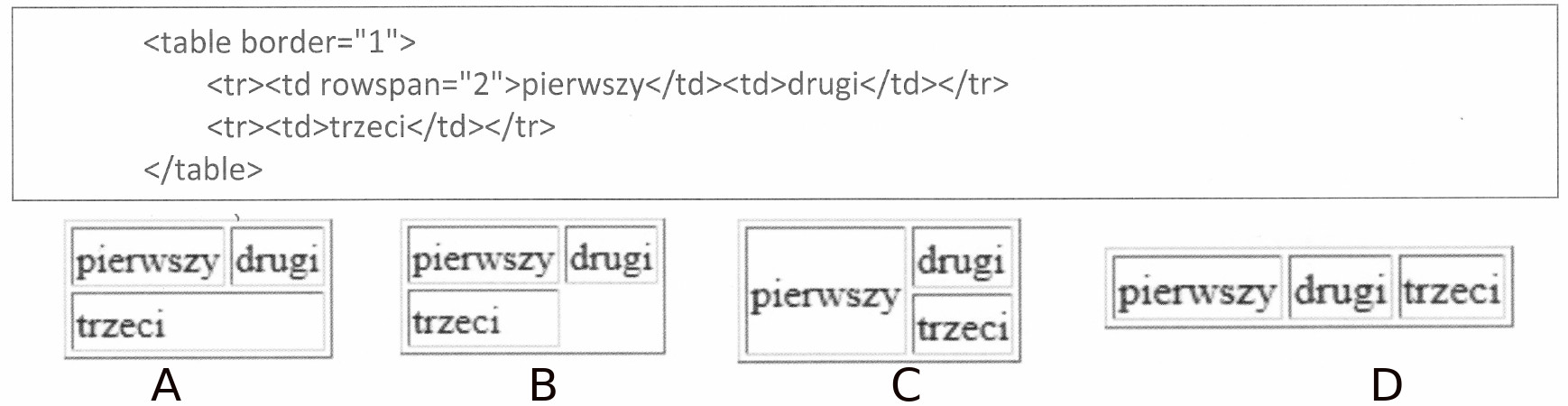
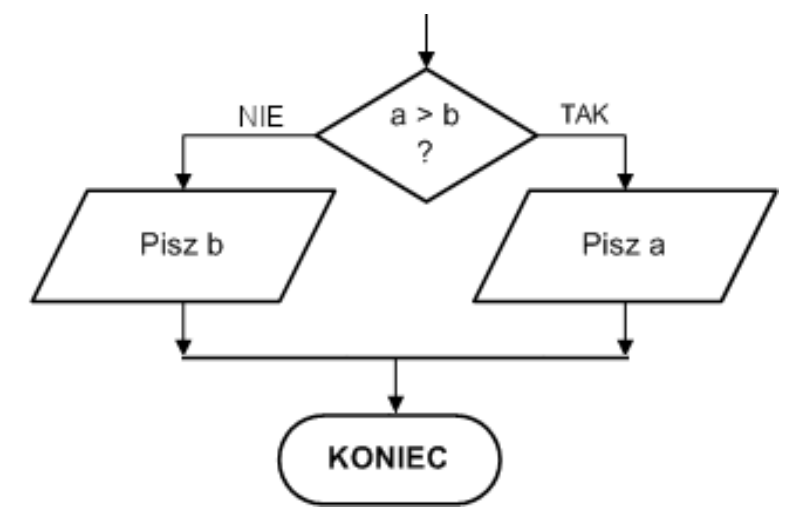
Pytanie 1
Wartości, które może przyjąć zmienna typu double, to:
A. "Ala"; 'd'
B. 1,44; 2,55
C. 2.4; 4; 3.2
D. 1979-12-05; 12:33
Zmienna typu double jest typem danych, który jest powszechnie używany w programowaniu, szczególnie w językach takich jak Java, C++ czy Python, do przechowywania liczb zmiennoprzecinkowych o podwójnej precyzji. W przeciwieństwie do typów całkowitych, typ double może reprezentować liczby z częścią dziesiętną, co czyni go idealnym do obliczeń wymagających precyzyjnych wartości, takich jak obliczenia finansowe czy naukowe. Przykłady wartości, które mogą być przechowywane w zmiennej typu double obejmują 2.4, 4, 3.2, gdzie każda z nich jest liczbą zmiennoprzecinkową. Ważne jest, aby stosować ten typ w odpowiednich kontekstach, aby uniknąć błędów związanych z precyzją. Zgodnie z najlepszymi praktykami, podczas definiowania zmiennych należałoby jasno określić ich typ, aby zapewnić przejrzystość kodu oraz jego przyszłą konserwację.