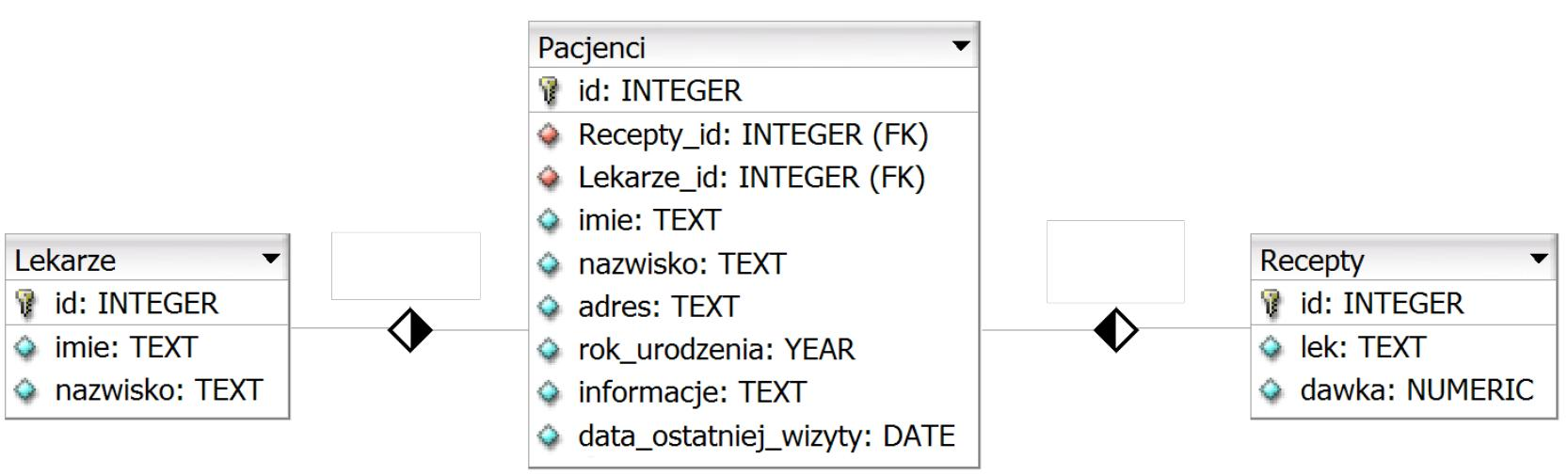
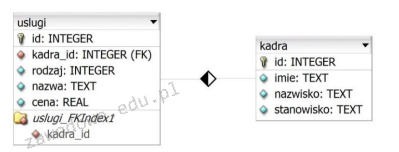
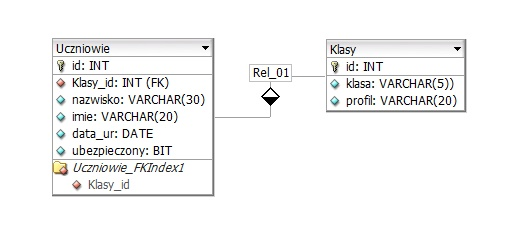
Pytanie 1
Relacja opisana jako: "Rekord z tabeli A może odpowiadać wielu rekordom z tabeli B. Każdemu rekordowi z tabeli B przyporządkowany jest dokładnie jeden rekord z tabeli A" jest relacją
A. wiele do wielu
B. nieoznaczoną
C. jeden do wielu
D. jeden do jednego
Relacja typu jeden do wielu oznacza, że jeden rekord z jednej tabeli (w tym przypadku tabela A) może być powiązany z wieloma rekordami z innej tabeli (tabela B). W opisanej sytuacji rekord z tabeli A może odpowiadać dowolnej liczbie rekordów z tabeli B, co ilustruje tę relację. Przykładem takiej relacji może być baza danych systemu zarządzania szkołą, gdzie jeden nauczyciel (rekord z tabeli A) może uczyć wielu uczniów (rekordy z tabeli B), ale każdy uczeń jest przypisany do jednego nauczyciela. Przy projektowaniu baz danych, stosowanie odpowiednich relacji jest kluczowe dla integralności i wydajności systemu. Dbałość o takie relacje przyczynia się do poprawy jakości danych oraz minimalizacji redundancji, co jest zgodne z zasadami normalizacji baz danych. W praktyce, relacje jeden do wielu są powszechnie stosowane w systemach CRM, ERP oraz wielu innych aplikacjach, które wymagają organizacji danych w sposób logiczny i praktyczny.