Pytanie 1
Na podstawie przydzielenia wartości do zmiennych w języku PHP można zauważyć, że
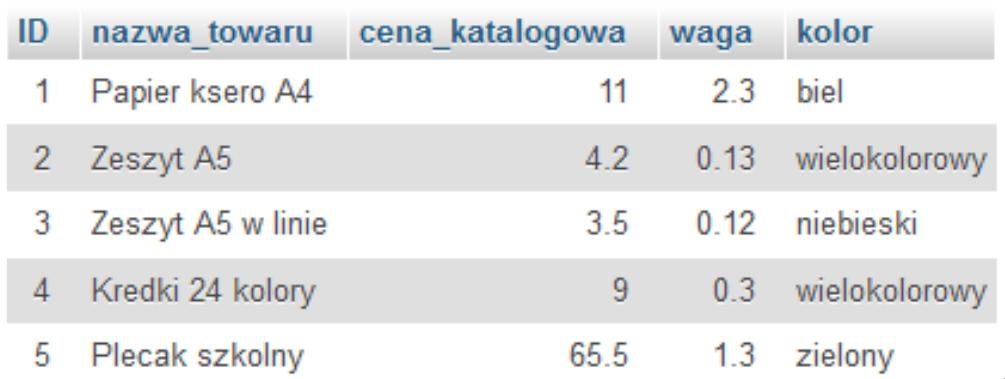
$zmienna1 = 15; $zmienna2 = "15"; $zmienna3 = (string) $zmienna1;
A. zmienna1 i zmienna3 mają ten sam typ.
B. zmienna2 i zmienna3 mają ten sam typ.
C. zmienna1 i zmienna2 mają ten sam typ.
D. wszystkie zmienne mają ten sam typ.
Nie do końca to jest dobre, co mówisz, bo $zmienna1 to liczba całkowita (integer), a $zmienna2 to string. Typy danych w PHP mają znaczenie, bo różnie się zachowują w trakcie działania. Liczby są liczone, a teksty traktowane jako znaki. Mimo że obie pokazują "15", to ich typy są inne, co może prowadzić do błędów. Z $zmienna1 i $zmienna3 też jest nieciekawie, bo mimo że to liczby, to jednak typy się różnią - $zmienna1 to integer, a $zmienna3 to string. Często można się w tym pogubić, zakładając, że mając te same wartości, są też tego samego typu. Jak mówisz, że trzy zmienne są takie same, to pokazujesz, że nie do końca masz jasność co do typów w PHP. Pamiętaj, żeby zwracać uwagę na rzutowanie typów, bo niedopatrzenia mogą skutkować problemami w kodzie. Rekomenduję, żeby programiści regularnie sięgać do dokumentacji i używać dobrych praktyk, by lepiej ogarnąć temat typów danych w swoich projektach.