Pytanie 1
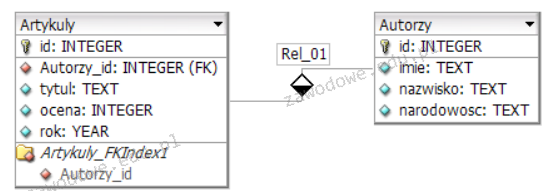
Na ilustracji pokazano relację jeden do wielu. Łączy ona

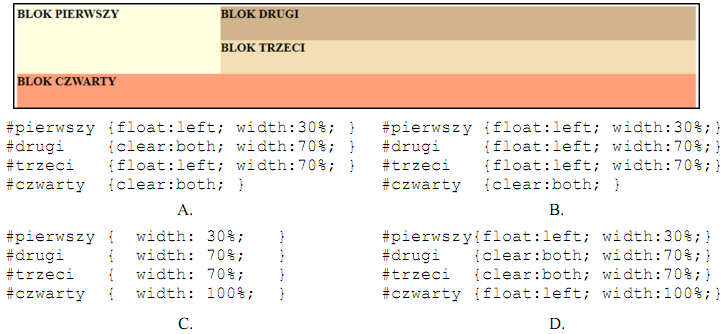
A. klucz obcy rezyserzy_id tabeli filmy z kluczem obcym id tabeli rezyserzy
B. klucz podstawowy id tabeli filmy z kluczem obcym rezyserzy_id tabeli rezyserzy
C. klucz obcy rezyserzy_id tabeli filmy z kluczem podstawowym id tabeli rezyserzy
D. klucz podstawowy id tabeli filmy z kluczem podstawowym id tabeli rezyserzy
Relacja jeden do wielu w bazach danych często wiąże się z sytuacją, gdzie jeden rekord w tabeli nadrzędnej może być powiązany z wieloma rekordami w tabeli podrzędnej. W tym kontekście tabela nadrzędna to rezyserzy posiadająca klucz podstawowy id, natomiast tabela podrzędna to filmy która odnosi się do tej wartości poprzez klucz obcy rezyserzy_id. Klucz podstawowy to unikalny identyfikator rekordu w tabeli, który pozwala na jednoznaczne rozróżnienie każdego rekordu. Klucz obcy natomiast jest atrybutem w tabeli podrzędnej, który odnosi się do klucza podstawowego w tabeli nadrzędnej. Jest to zgodne z teorią normalizacji baz danych, gdzie relacje jeden do wielu są standardowym podejściem do projektowania struktur danych. Użycie klucza obcego pozwala na utrzymanie integralności referencyjnej, co oznacza że każda wartość klucza obcego musi odpowiadać wartości klucza podstawowego w powiązanej tabeli lub być null, jeśli taka relacja jest dozwolona. Praktyczne zastosowanie tej relacji można zaobserwować w systemach zarządzania treścią, gdzie jeden autor (reżyser) może mieć przypisanych wiele artykułów (filmów), jednak każdy artykuł jest przypisany do jednego autora, co umożliwia na przykład efektywne zarządzanie danymi i generowanie raportów o twórczości danego autora.