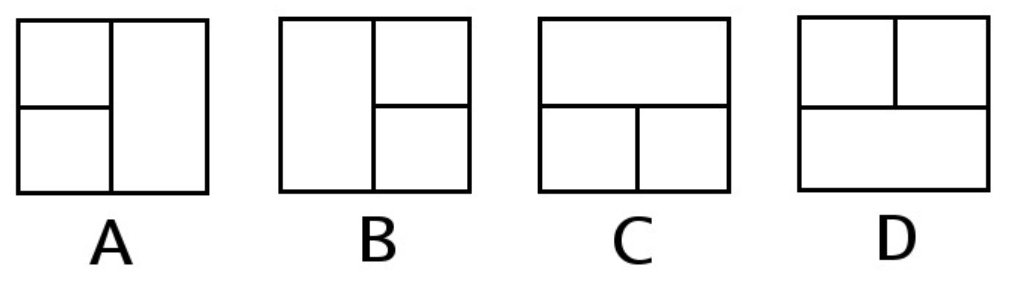
Pytanie 1
Aby zwiększyć wydajność operacji na bazie danych, należy dla pól, które są często wyszukiwane lub sortowane
A. dodać więzy integralności
B. stworzyć osobną tabelę przechowującą tylko te pola
C. dodać klucz obcy
D. utworzyć indeks
Praca nad dobrą wydajnością baz danych wymaga, żeby zrozumieć, że różne metody optymalizacji mają swoje cele, a działają w różny sposób. Jak dodasz klucz obcy do tabeli, to nie przyspieszysz wyszukiwania czy sortowania danych. Ten klucz ma inne zadanie, na przykład dba o to, żeby każdy rekord w tabeli 'Zamówienia' odnosił się do klienta w tabeli 'Klienci'. To jest ważne, ale nie zwiększy szybkości operacji. Wprowadzenie różnych reguł, jak unikalność czy not null, też nie przyspieszy wyszukiwania, lecz chroni dane przed błędami. Czasami lepiej jest stworzyć osobną tabelę, ale to może skomplikować strukturę bazy danych i wprowadzić więcej kłopotów przy zarządzaniu, zwłaszcza z relacjami między tabelami. Źle przeprowadzona optymalizacja bazy danych może prowadzić do tego, że system będzie wolniejszy przez nadmiarowość. Dlatego ważne jest, żeby dobrze rozumieć różnice między technikami i jak je stosować, żeby osiągnąć najlepsze wyniki w wydajności bazy danych.