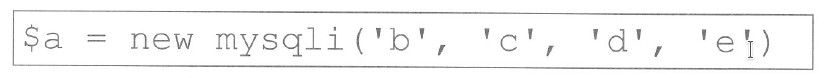Pytanie 1
Czego nie należy brać pod uwagę przy zabezpieczaniu serwera bazy danych przed atakami hakerskimi?
A. Aktywacja zapory
B. Defragmentacja dysków
C. Zamykanie portów związanych z bazą danych
D. Używanie skomplikowanych haseł do bazy
Defragmentacja dysków, mimo że może poprawić wydajność dysków twardych, nie jest bezpośrednio związana z zabezpieczeniem serwera bazy danych przed atakami hakerów. Zabezpieczenia bazy danych powinny koncentrować się na praktykach, które bezpośrednio wpływają na ochronę danych i dostęp do nich. Przykładem skutecznych środków ochrony są złożone hasła, które utrudniają nieautoryzowany dostęp do systemu. Stosowanie silnych haseł, które łączą litery, cyfry oraz znaki specjalne, jest podstawowym krokiem w kierunku zabezpieczenia bazy danych. Kolejnym aspektem jest blokowanie portów, które nie są niezbędne do działania bazy danych, co może znacznie ograniczyć możliwości ataku z sieci. Włączenie zapory (firewall) także przyczynia się do ochrony, monitorując i kontrolując ruch sieciowy. Warto podkreślić, że zgodnie z zasadami bezpieczeństwa, minimalizacja punktów dostępu do bazy danych jest kluczowa dla jej ochrony.