Pytanie 1
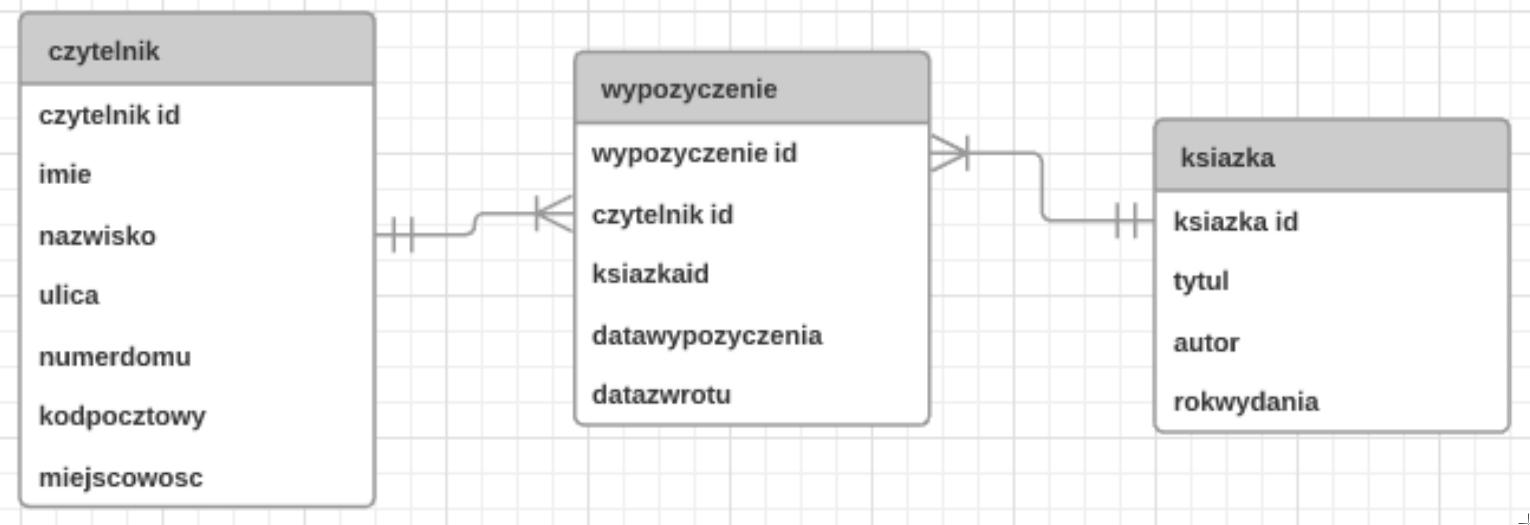
Baza danych zawiera tabelę uczniowie z kolumnami: imie, nazwisko, klasa. Jakie polecenie SQL powinno być użyte, aby wyświetlić imiona i nazwiska uczniów, których nazwiska zaczynają się na literę M?
A. SELECT nazwisko, imie FROM uczniowie WHERE nazwisko IN "M%"
B. SELECT nazwisko, imie FROM uczniowie ORDER BY nazwisko = "M%"
C. SELECT nazwisko, imie FROM uczniowie WHERE nazwisko LIKE "M%"
D. SELECT nazwisko, imie FROM uczniowie ORDER BY nazwisko IN "M%"
Wybór opcji SELECT nazwisko, imie FROM uczniowie WHERE nazwisko LIKE "M%" jest poprawny, ponieważ używa klauzuli WHERE do filtrowania rekordów na podstawie warunków. Operator LIKE pozwala na wyszukiwanie wzorców w danych tekstowych, a symbol % jest używany jako wildcard, co oznacza, że zastępuje dowolny ciąg znaków. Dzięki temu zapytanie zwraca wszystkich uczniów, których nazwiska zaczynają się na literę M. Takie podejście jest zgodne z najlepszymi praktykami w SQL, gdzie klauzula WHERE jest fundamentalnym elementem selekcji danych. W praktyce, gdy chcemy wyszukiwać dane w bazach danych, użycie LIKE w połączeniu z symbolami wieloznacznymi (takimi jak %) jest powszechną techniką, stosowaną w aplikacjach webowych i systemach zarządzania danymi. Przykładowo, w systemie szkolnym, takie zapytanie może być używane do generowania listy uczniów w celu wysyłania powiadomień lub gromadzenia informacji o postępach w nauce.