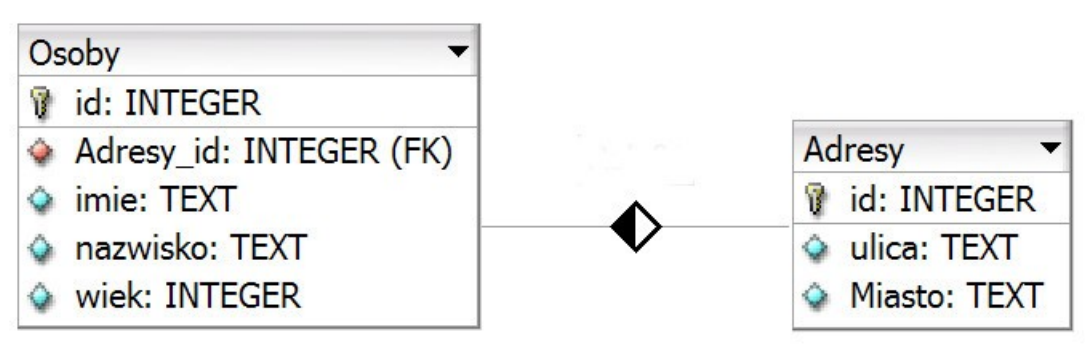
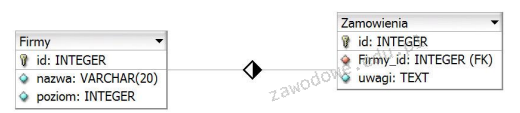
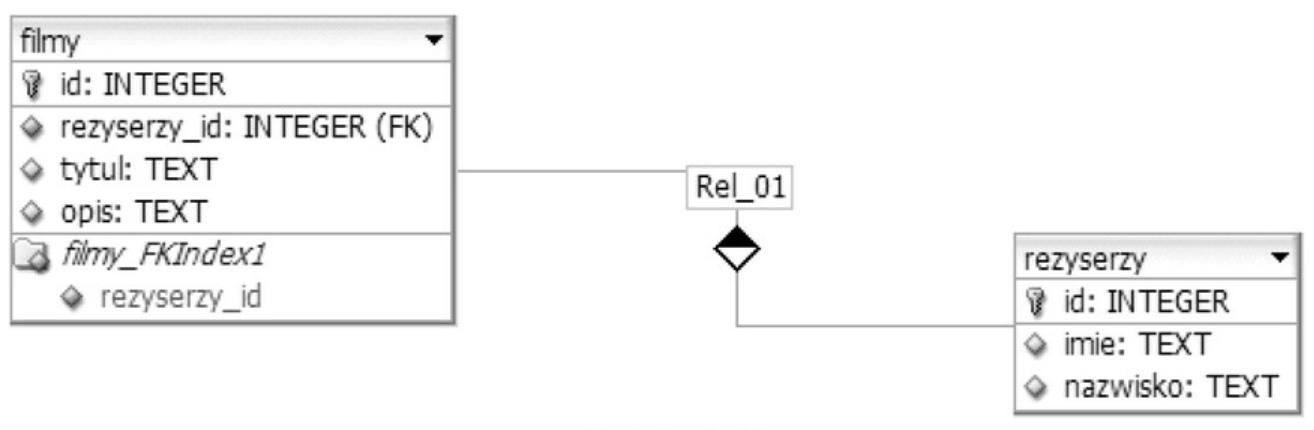
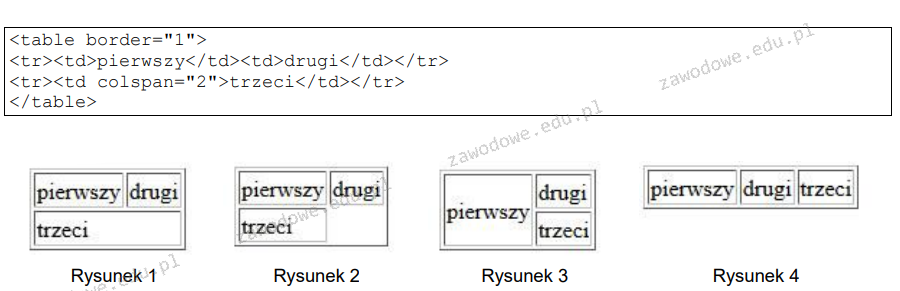
Pytanie 1
Jakim formatem plików dźwiękowych charakteryzuje się kompresja bezstratna?
A. MPEG
B. WAW
C. FLAC
D. MP3
MP3 to format dźwiękowy, który wykorzystuje kompresję, ale niestety jest to kompresja stratna, więc część danych audio się traci. Dlatego jakość dźwięku nie jest najlepsza, co może być problemem dla audiofilów, którzy szukają czegoś lepszego. Z kolei WAV to format nieskompresowany, co oznacza, że zachowuje wszystkie dane, ale pliki są duże… mało praktyczne, zwłaszcza jak masz ogromną bibliotekę muzyczną. MPEG, znany bardziej jako standard kompresji wideo, też może być używany do dźwięku, ale tak jak MP3, traci na jakości. Generalnie ani MP3, ani WAV, ani MPEG nie nadają się do kompresji bezstratnej, więc to nie są dobre odpowiedzi w tym przypadku.