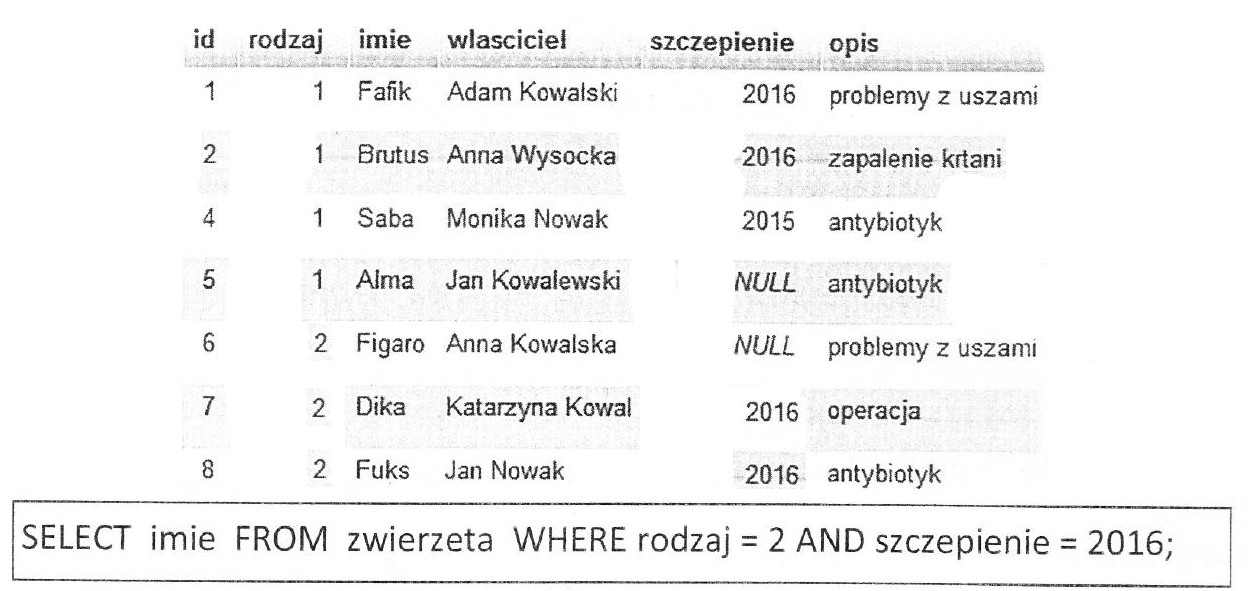
Pytanie 1
Dla jakich nazwisk użyta w zapytaniu klauzula LIKE jest poprawna?
| SELECT imie FROM mieszkancy WHERE imie LIKE '_r%'; |
A. Gerald, Jarosław, Marek, Tamara
B. Arleta, Krzysztof, Krystyna, Tristan
C. Rafał, Rebeka, Renata, Roksana
D. Krzysztof, Krystyna, Romuald
Prawidłowa odpowiedź Arleta Krzysztof Krystyna Tristan jest zgodna z klauzulą LIKE w języku SQL która pozwala na wyszukiwanie wzorców w danych tekstowych W zapytaniu użyto wzorca '_r%' gdzie podkreślenie oznacza dowolny pojedynczy znak a procent dowolną liczbę znaków W tym przypadku imiona muszą mieć 'r' jako drugi znak co jest spełnione dla Arleta Krzysztof Krystyna i Tristan Klauzula LIKE jest często używana w aplikacjach bazodanowych do filtrowania danych tekstowych na przykład w systemach zarządzania klientami gdzie można wyszukiwać nazwiska klientów zaczynające się na określoną literę Dobre praktyki zalecają ostrożne używanie wzorców które mogą prowadzić do pełnych skanów tabel co wpływa na wydajność Indeksowanie kolumn może poprawić szybkość zapytań LIKE jednak należy unikać wzorców zaczynających się od symbolu procenta gdyż pomijają indeksy Warto zrozumieć że LIKE jest potężnym narzędziem w SQL które może znacznie ułatwić pracę z tekstem jednak wymaga ono przemyślanego użycia by nie pogorszyć wydajności bazy danych