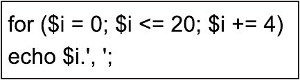Pytanie 1
Model barw o parametrach: odcień, nasycenie, jasność i przezroczystość, to
A. HSLA
B. CMYK
C. RGBA
D. SRGB
Prawidłowa odpowiedź to HSLA, bo dokładnie ten model opisuje kolor za pomocą czterech parametrów: odcień (Hue), nasycenie (Saturation), jasność (Lightness) i przezroczystość (Alpha). W praktyce w CSS zapis wygląda na przykład tak: `hsla(210, 50%, 40%, 0.7)`. Pierwsza wartość, odcień, to kąt na kole barw w stopniach (0–360), gdzie 0 to czerwony, 120 to zielony, 240 to niebieski itd. Nasycenie i jasność zapisujemy w procentach – nasycenie określa „intensywność” koloru, a jasność to to, czy kolor jest ciemny czy bardzo rozjaśniony. Ostatni parametr, alpha, to kanał przezroczystości w zakresie od 0 (całkowicie przezroczysty) do 1 (całkowicie nieprzezroczysty). Moim zdaniem HSLA jest dużo wygodniejszy od klasycznego RGB przy projektowaniu interfejsów, bo łatwiej myśleć w kategoriach „przyciemnij ten kolor o 20%” albo „zmniejsz trochę nasycenie”, niż ręcznie kombinować z trzema składowymi R, G i B. W nowoczesnym front-endzie często stosuje się HSLA do definiowania palet kolorów, np. w zmiennych CSS, właśnie dlatego, że łatwo jest tworzyć spójne warianty: hover, focus, disabled, tła, obramowania. Dobre praktyki w UI/UX mówią, żeby trzymać stały odcień (Hue) dla jednego typu akcji, a zmieniać głównie jasność i nasycenie, żeby uzyskać różne stany tego samego koloru. Warto też wiedzieć, że HSLA to tak naprawdę tylko inny sposób zapisu kolorów w przestrzeni RGB, ale dużo bardziej „ludzki” w obsłudze. Przeglądarki zgodne ze standardami CSS3 i nowszymi w pełni wspierają HSLA, więc spokojnie można go używać w projektach komercyjnych. Dobrą praktyką jest także świadome korzystanie z kanału alpha, np. do półprzezroczystych nakładek, cieni czy tła pod modale, zamiast używania grafik PNG z przezroczystością.