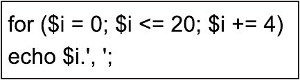Pytanie 1
Gdzie powinien być umieszczony znacznik meta w języku HTML?
A. w obrębie znaczników <body> ... </body>
B. w dolnej części witryny internetowej.
C. w sekcji nagłówkowej strony.
D. w obrębie znaczników paragrafu.
Znacznik meta języka HTML jest kluczowym elementem, który powinien znajdować się w sekcji nagłówkowej witryny, oznaczonej znacznikami <head> ... </head>. Znaczniki meta dostarczają przeglądarkom oraz wyszukiwarkom internetowym informacji o stronie, takich jak jej opis, słowa kluczowe, a także informacje dotyczące kodowania czy autorstwa. Przykładowo, znacznik <meta charset="UTF-8"> informuje przeglądarkę o używanym kodowaniu znaków, co jest istotne dla prawidłowego wyświetlania tekstu w różnych językach. Dodatkowo, metadane takie jak <meta name="description" content="Opis strony"> są często wykorzystywane przez wyszukiwarki do generowania opisów w wynikach wyszukiwania, co może wpłynąć na wskaźnik klikalności (CTR) w SERP. Warto również dodać, że znaczniki meta mogą być używane do definiowania polityki prywatności i zabezpieczeń, na przykład poprzez <meta http-equiv="X-UA-Compatible" content="IE=edge">. Użycie odpowiednich metadanych w nagłówku jest zatem kluczowe dla optymalizacji SEO oraz zapewnienia odpowiedniej interakcji użytkowników z witryną.