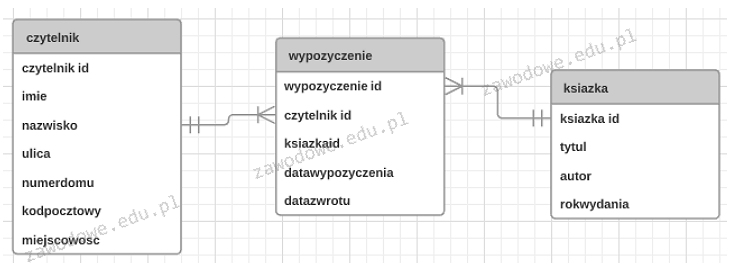
phpMyAdmin wielu osobom kojarzy się po prostu z „tym panelem w przeglądarce”, więc łatwo tu o pomyłkę co on właściwie administruje. Warto to sobie dobrze uporządkować, bo miesza się tu kilka warstw: serwer WWW, protokoły, pliki na serwerze i serwer baz danych. phpMyAdmin jest aplikacją webową napisaną w PHP, która służy jako graficzny interfejs do zarządzania serwerem baz danych MySQL lub MariaDB. To oznacza, że jego głównym zadaniem jest operowanie na strukturach bazodanowych i danych, a nie bezpośrednie zarządzanie serwerem WWW. Odpowiedź „WWW” bywa kusząca, bo faktycznie uruchamiasz phpMyAdmina w przeglądarce pod adresem HTTP/HTTPS, często zintegrowanym z panelem hostingu. Ale serwer WWW (np. Apache, Nginx) to osobna usługa, która tylko „serwuje” interfejs phpMyAdmina. Konfigurację wirtualnych hostów, certyfikatów SSL, modułów itp. ogarnia się zupełnie innymi narzędziami i plikami konfiguracyjnymi, a nie przez phpMyAdmina. Mylenie tych ról to typowy błąd: skoro coś jest w przeglądarce, to ludzie myślą, że to narzędzie do WWW, a tu chodzi o warstwę danych. Podobnie jest z odpowiedzią „FTP”. FTP to protokół do przesyłania plików między klientem a serwerem, używa się go np. do wrzucania plików strony na hosting. phpMyAdmin nie zarządza serwerem FTP, nie ustawia kont FTP, nie przerzuca plików po tym protokole. Owszem, czasem możesz wyeksportować bazę do pliku i potem go pobrać, ale to jest zwykłe pobieranie HTTP, nie administracja FTP. Odpowiedź „plików” też jest myląca, bo w phpMyAdminie widzisz dane w formie tabel i rekordów, a nie jako system plików. Pliki na serwerze (PHP, HTML, CSS, grafiki) leżą w katalogach systemu operacyjnego, zarządza się nimi przez FTP, SFTP, SSH albo menedżer plików w panelu hostingu. phpMyAdmin nie służy do przenoszenia katalogów, zmiany uprawnień plików systemowych czy instalowania aplikacji przez kopiowanie plików. On operuje na poziomie SQL: SELECT, INSERT, UPDATE, DELETE, ALTER TABLE itd. Typowy błąd myślowy polega na wrzuceniu „wszystkiego, co jest w panelu hostingu” do jednego worka. Tymczasem dobra praktyka w administracji i programowaniu webowym to rozumieć podział ról: serwer WWW serwuje strony, serwer FTP/SSH obsługuje pliki, a serwer baz danych trzyma dane aplikacji. phpMyAdmin jest właśnie wygodnym interfejsem do tego trzeciego elementu – serwera baz danych, a nie do całej reszty infrastruktury.