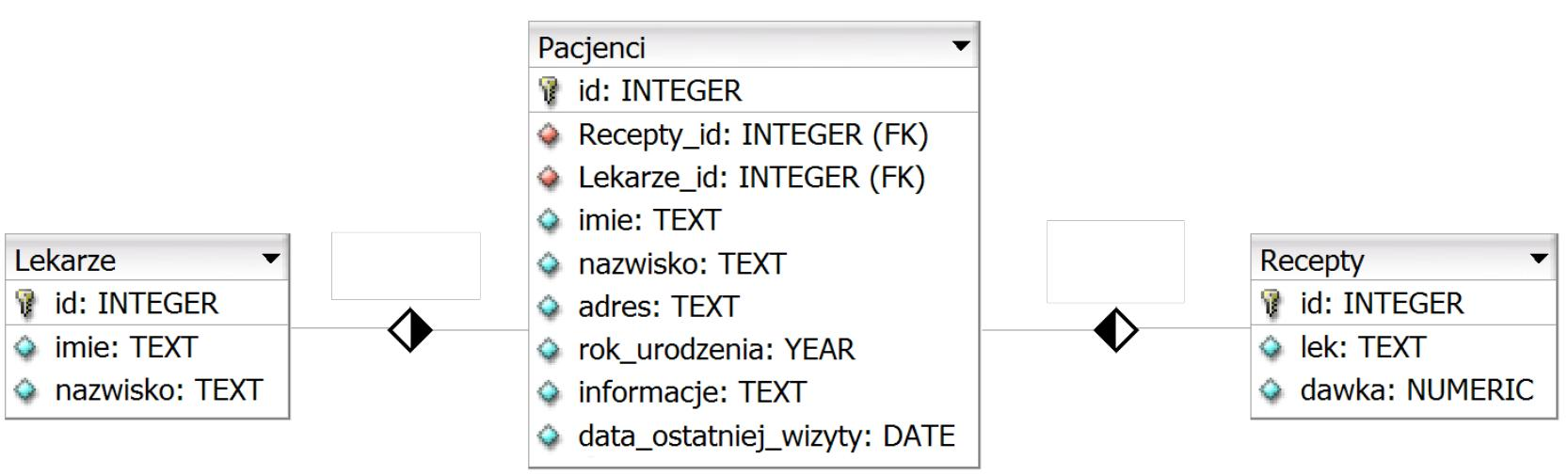
Pytanie 1
Na ilustracji przedstawiono dwie tabele. Aby ustanowić między nimi relację jeden do wielu, gdzie jedna strona to Klienci, a druga strona to Zamowienia, należy
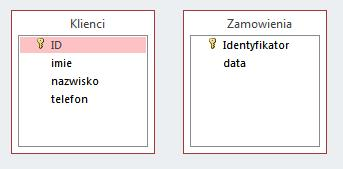
A. wprowadzić pole klucza obcego do tabeli Zamowienia i powiązać je z ID tabeli Klienci.
B. powiązać relacją pola ID z obu tabel.
C. stworzyć trzecią tabelę z dwoma kluczami obcymi. Jeden klucz połączyć z ID tabeli Klienci, a drugi klucz połączyć z ID tabeli Zamowienia.
D. dodać pole klucza obcego do tabeli Klienci i powiązać je z ID tabeli Zamowienia.
Tworzenie relacji jeden do wielu między tabelami w bazie danych wymaga zrozumienia, jak działa klucz podstawowy i klucz obcy. W tym przypadku tabela Klienci posiada pole ID, które jest kluczem podstawowym. Aby utworzyć relację jeden do wielu, należy dodać do tabeli Zamowienia pole klucza obcego, które będzie połączone z polem ID z tabeli Klienci. Dzięki temu każdy rekord w tabeli Zamowienia będzie mógł być przypisany do jednego klienta, ale jeden klient może mieć wiele zamówień. Taka struktura jest zgodna z normalizacją baz danych, która ma na celu eliminację redundancji danych i zapewnienie integralności danych. W praktyce, w systemach takich jak SQL, relacje te są wykorzystywane do wykonywania operacji takich jak wyszukiwanie wszystkich zamówień dla konkretnego klienta, co jest wykonywane przez dołączenie tabel za pomocą klucza obcego. Implementacja kluczy obcych w bazach danych jest standardową praktyką, która zwiększa spójność i bezpieczeństwo danych, minimalizując ryzyko błędów podczas operacji CRUD (Create Read Update Delete).