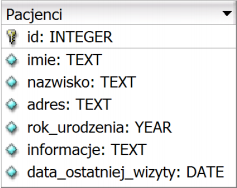
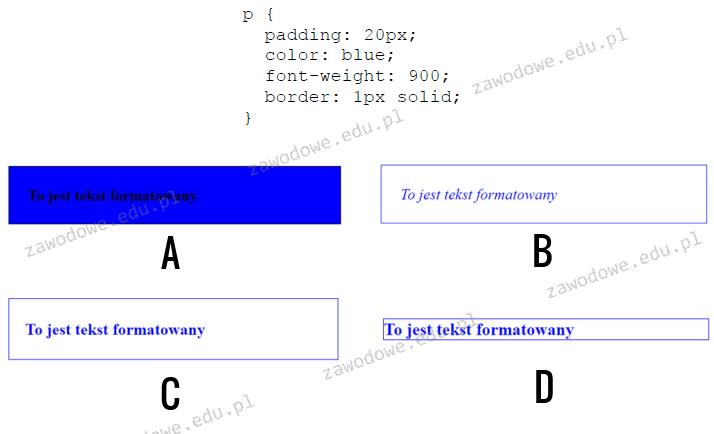
Pytanie 1
Który protokół jest stosowany do przesyłania plików na serwer WWW?
A. FTP
B. DHCP
C. POP3
D. DNS
FTP, czyli File Transfer Protocol, to protokół używany do przesyłania plików między komputerami w sieci, zwłaszcza w kontekście serwerów WWW. Umożliwia on użytkownikom łatwe przesyłanie, pobieranie, a także zarządzanie plikami na serwerze. FTP działa na bazie modelu klient-serwer, gdzie klient nawiązuje połączenie z serwerem i może przesyłać pliki w obie strony. Protokół ten operuje na portach 20 i 21, co czyni go standardem w dziedzinie przesyłania plików. W praktyce, wiele aplikacji klienckich, takich jak FileZilla czy WinSCP, wykorzystuje FTP do zarządzania plikami na serwerach. FTP wspiera różne metody autoryzacji, w tym logowanie anonimowe, co umożliwia użytkownikom dostęp do publicznych zasobów. Warto również zaznaczyć, że istnieją rozszerzenia, takie jak FTPS czy SFTP, które oferują dodatkowe funkcje zabezpieczeń, umożliwiając szyfrowanie danych podczas transferu. W kontekście standardów, FTP jest definiowany w dokumentach RFC 959 oraz RFC 3659, które określają jego działanie oraz interakcje w sieci. Dzięki swojej wszechstronności i niezawodności, FTP pozostaje jednym z najpopularniejszych protokołów do przesyłania plików w Internecie.