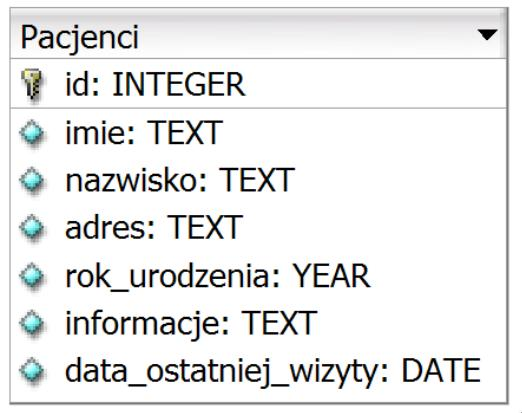
Pytanie 1
W tabeli pracownicy utworzono klucz główny typu INTEGER z atrybutami NOT NULL oraz AUTO-INCREMENT. Dodatkowo zdefiniowano pola imie oraz nazwisko. W przypadku użycia przedstawionej w ramce kwerendy SQL wprowadzającej dane, gdzie pominięto pole klucza, w bazie danych MySQL dojdzie do

A. błędu związane z nieprawidłową liczbą pól
B. wprowadzenia rekordu do tabeli, dla klucza głównego zostanie przypisana kolejna wartość naturalna
C. wprowadzenia rekordu do tabeli, dla klucza głównego zostanie przypisana wartość NULL
D. zignorowania polecenia, tabela nie ulegnie zmianie
W przypadku bazy danych MySQL, klucz główny zdefiniowany z atrybutem AUTO-INCREMENT pełni ważną funkcję automatycznego przydzielania unikalnych wartości liczbowych dla każdego nowego rekordu. Jest to szczególnie przydatne w dużych bazach danych, gdzie ręczne przypisywanie wartości klucza mogłoby prowadzić do błędów czy konfliktów. W przedstawionym przypadku, query SQL typu INSERT INTO pracownicy (imie, nazwisko) VALUES ('Anna', 'Nowak'); pomija pole klucza głównego. Dzięki zastosowaniu AUTO-INCREMENT, MySQL automatycznie przydzieli nową wartość klucza głównego, która będzie kolejną w sekwencji, zapewniając integralność danych. Tego rodzaju mechanizm jest standardem w zarządzaniu relacyjną bazą danych, co pozwala na efektywne i bezpieczne operowanie danymi bez ryzyka wystąpienia błędów związanych z ręcznym zarządzaniem kluczami. Dobre praktyki sugerują, aby w takich przypadkach polegać na funkcji AUTO-INCREMENT, co nie tylko ułatwia pracę z bazą danych, ale również minimalizuje możliwość wystąpienia duplikatów czy niespójności w danych. To podejście jest szeroko stosowane w branży IT, szczególnie w przypadkach systemów wymagających dużego wolumenu danych.