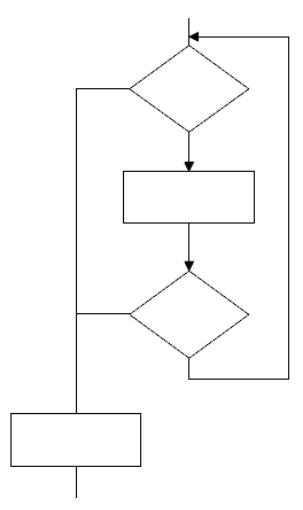
Pytanie 1
W języku HTML, aby uzyskać efekt podobny do tego w przykładzie, trzeba użyć konstrukcji

A. <p><big>Duży tekst</big> zwykły tekst</p>
B. <p><big>Duży tekst</p> zwykły tekst
C. <p><strike>Duży tekst zwykły tekst</p>
D. <p><strike>Duży tekst</strike> zwykły tekst</p>
Odpowiedź jest prawidłowa, ponieważ w języku HTML, aby zwiększyć rozmiar czcionki dla części tekstu, można użyć znacznika <big>. Znacznik ten powoduje, że tekst wewnątrz jest wyświetlany w większym rozmiarze niż tekst otaczający. Jest to przydatne w sytuacjach, gdy chcemy wyróżnić część tekstu bez stosowania zaawansowanego stylu CSS. Chociaż <big> jest uznawany za przestarzały w nowoczesnym HTML, dla celów edukacyjnych i zgodności z starszymi dokumentami HTML wciąż może być stosowany. Praktyką zalecaną w aktualnych standardach jest używanie stylów CSS, np. poprzez przypisanie klasy lub bezpośrednie stylowanie in-line. Warto zaznaczyć, że stosowanie <big> nie jest zalecane w nowych projektach, ponieważ CSS oferuje większą elastyczność i kontrolę nad wyglądem tekstu. Niemniej jednak, znajomość takich znaczników jak <big> pomaga w zrozumieniu, jak rozwijał się HTML i jakie są różnice między starszymi a nowoczesnymi metodami formatowania tekstu.