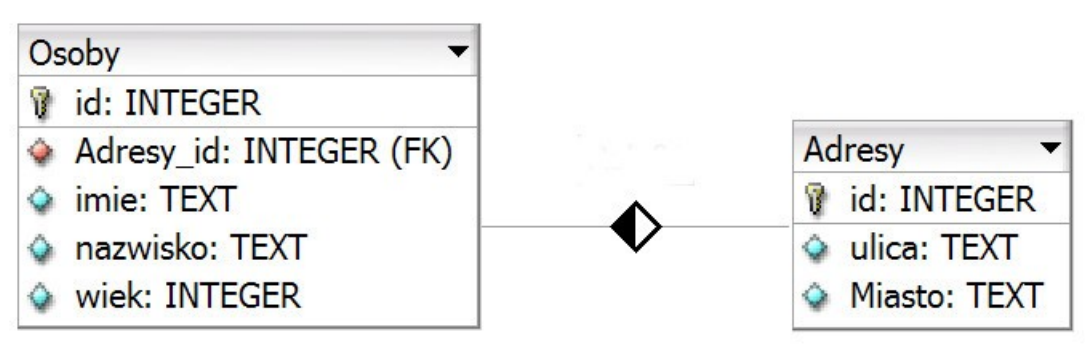
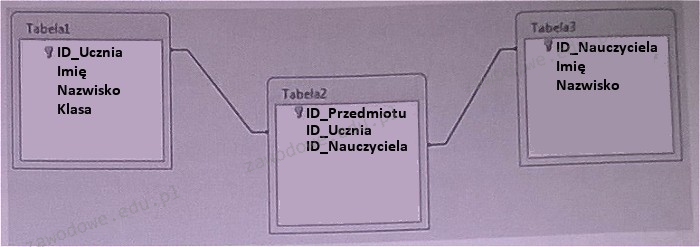
Pytanie 1
Określ rodzaj powiązania pomiędzy tabelami: Tabela1 oraz Tabela3
A. Wiele do wielu
B. Jeden do wielu
C. Wiele do jednego
D. Jeden do jednego
Relacja wiele do wielu między tabelami Tabela1 i Tabela3 jest prawidłowym rozwiązaniem, ponieważ relacja ta umożliwia powiązanie wielu rekordów z jednej tabeli z wieloma rekordami z drugiej tabeli. W kontekście przedstawionego schematu baz danych, tabela Tabela1 przechowuje informacje o uczniach, podczas gdy Tabela3 zawiera dane o nauczycielach. Tabela2 pełni rolę tabeli pośredniej, zawierającej klucze obce, które łączą ID_Ucznia z ID_Nauczyciela za pomocą ID_Przedmiotu jako dodatkowego klucza. To podejście jest powszechnie stosowane w projektowaniu baz danych, aby zapewnić elastyczność i możliwość zaawansowanej analizy danych, np. którzy uczniowie mają zajęcia z jakimi nauczycielami. W praktyce takie rozwiązanie stosuje się w systemach edukacyjnych, gdzie każdy uczeń może uczęszczać na zajęcia prowadzone przez różnych nauczycieli, a każdy nauczyciel może prowadzić zajęcia dla wielu uczniów. Standardy projektowania relacyjnych baz danych, takie jak normalizacja, zalecają tego rodzaju architekturę, aby uniknąć redundancji danych i umożliwić efektywne zarządzanie złożonymi relacjami. Tabele pośrednie, takie jak Tabela2, są kluczowym elementem w tworzeniu relacji wiele do wielu, ponieważ umożliwiają mapowanie skomplikowanych powiązań w sposób technicznie poprawny i zrozumiały dla użytkowników systemu.