Który z znaczników ma na celu organizację struktury tekstu w HTML?
A. <u>
B. <head>
C. <style>
D. <h6>
Znacznik <u> służy do podkreślenia tekstu, co nie ma nic wspólnego z tworzeniem hierarchii treści. W dzisiejszych standardach HTML, podkreślenie tekstu powinno być używane bardzo ostrożnie, ponieważ może wprowadzać w błąd czytelników i wyszukiwarki, sugerując, że tekst jest linkiem do innej strony. W praktyce, znaczenie podkreślenia powinno ograniczać się do przypadków, gdzie jest to konieczne, a nie stać się domyślnym sposobem na wyróżnienie treści. Z kolei znacznik <head> pełni rolę sekcji nagłówkowej dokumentu HTML, w której znajduje się metadane, takie jak tytuł, skrypty czy style. Nie ma on żadnego zastosowania w kontekście budowania hierarchii tekstu, ponieważ nie wpływa na sposób, w jaki treść jest wyświetlana na stronie. Ponadto, znacznik <style> jest używany do definiowania stylów CSS, co również nie ma związku z hierarchią tekstu. Typowe błędy myślowe, które prowadzą do takich niepoprawnych wniosków, mogą wynikać z mylenia celów różnych znaczników HTML. Każdy znacznik ma swoje specyficzne funkcje, a ich niewłaściwe użycie może prowadzić do nieefektywnej struktury strony oraz negatywnie wpływać na doświadczenia użytkowników i SEO. Zrozumienie roli każdego elementu w HTML jest kluczowe dla tworzenia przejrzystych i funkcjonalnych stron internetowych.
Pytanie 2
Poziom izolacji transakcji Repeatable Read (tryb powtarzalnego odczytu) używany przez MS SQL jest związany z problemem
A. brudnych odczytów
B. utraty aktualizacji
C. niepowtarzalnych odczytów
D. odczytów widm
Wybór odpowiedzi 'niepowtarzalnych odczytów', 'brudnych odczytów' lub 'utraty aktualizacji' wskazuje na brak zrozumienia, jak działają różne poziomy izolacji transakcji w kontekście baz danych. Odczyty niepowtarzalne polegają na tym, że transakcja może odczytać różne wartości w kolejnych odczytach tego samego wiersza, co jest problemem rozwiązywanym przez poziom Repeatable Read. Oznacza to, że dane odczytane w jednym kroku transakcji pozostają spójne do końca tej transakcji, a zatem nie są one narażone na zmiany poprzez inne transakcje w tym samym czasie. Brudne odczyty występują, gdy jedna transakcja odczytuje dane zapisane przez inną, jeszcze niezakończoną transakcję, co jest problemem z kolei eliminowanym przez poziomy izolacji takie jak Read Committed. Utrata aktualizacji to inny problem, który polega na tym, że dwie transakcje odczytują tę samą wartość i zapisują zmodyfikowane wartości, przy czym ostatnia zapisuje nadpisując wcześniejszą, co także nie jest bezpośrednim problemem w kontekście Repeatable Read. W praktyce, zrozumienie różnicy między tymi problemami jest kluczowe dla zapewnienia spójności transakcji. Warto zatem studiować dokumentację i standardy, aby właściwie dobierać poziomy izolacji w zależności od wymagań konkretnej aplikacji.
Pytanie 3
Przypisanie wartości do zmiennej $dana = 125; zapisane jest w języku
A. Python
B. C++
C. PHP
D. JavaScript
Zapis $dana = 125; na pierwszy rzut oka może wyglądać jak zwykłe przypisanie znane z wielu języków, ale kluczowy jest tutaj znak dolara przed nazwą zmiennej. Właśnie ten prefiks odróżnia PHP od takich języków jak C++, Python czy czysty JavaScript. W tych trzech technologiach zmienne nie są oznaczane znakiem $, albo używa się go w zupełnie innym kontekście. W C++ standardowa deklaracja zmiennej liczbowej wygląda np. tak: int dana = 125; lub auto dana = 125;. Trzeba podać typ (lub pozwolić kompilatorowi go wywnioskować), a nazwa zmiennej nie ma żadnego prefiksu. Zapis ze znakiem $ nie jest zgodny ze składnią C++ i zwyczajnie się nie skompiluje. Błąd myślowy często wynika z tego, że ktoś kojarzy średnik na końcu i myśli: „aha, to pewnie C++ albo coś podobnego”, ale sam średnik to za mało, żeby poprawnie zidentyfikować język. W Pythonie sytuacja jest odwrotna: nie ma średników na końcu linii (są opcjonalne i praktycznie się ich nie używa), a nazwy zmiennych absolutnie nie mogą zaczynać się od $. Poprawny zapis w Pythonie to po prostu dana = 125. Python mocno stawia na czytelność i prostotę składni, dlatego takie ozdobniki jak $ są tam całkowicie zbędne. Wiele osób, które zaczynają przygodę z programowaniem webowym, myli Pythona z PHP, bo oba są dynamicznie typowane, ale składnia zmiennych jest zupełnie inna. JavaScript też nie używa $ jako obowiązkowego prefiksu. Co prawda $ może być częścią nazwy zmiennej (np. w jQuery: var $elem = $('#id');), ale nie jest to stały wymóg języka. Kluczowe jest to, że w nowoczesnym JavaScript zmienne deklarujemy przez let, const albo var: let dana = 125;. Samo $dana = 125; bez słowa kluczowego też jest formalnie możliwe w trybie nie–strict, ale jest to uznawane za bardzo złą praktykę, bo tworzy zmienną globalną i nie wygląda jak typowy, poprawny fragment kodu z dokumentacji czy podręczników. W kontekście tego pytania chodzi o rozpoznanie charakterystycznej składni, a nie o sztuczne przykłady z błędami. Typowy błąd przy takich zadaniach polega na tym, że ktoś skupia się tylko na jednym elemencie składni, np. na średniku, i ignoruje resztę. W programowaniu webowym warto patrzeć na całość: prefiksy, słowa kluczowe, styl zapisu. Wzorzec $zmienna = wartość; jest bardzo mocno związany z PHP i to właśnie pozwala poprawnie zaklasyfikować ten fragment kodu.
Pytanie 4
$n = '[email protected]'; $dl = strlen($n); $i = 0; while ($i < $dl && $n[$i] != '@') { echo $n[$i]; $i++; } Fragment kodu w języku PHP wyświetli
Analizując niepoprawne odpowiedzi, warto zwrócić uwagę na kilka kluczowych aspektów. W przypadku odpowiedzi, która wskazuje na wypisanie nazwy konta ze znakiem '@', należy zauważyć, że kod w rzeczywistości nie wlicza znaku '@' do wypisywanej wartości. Działanie pętli opiera się na warunku przerywającym, który kończy iterację przed napotkaniem '@', co oznacza, że nie może on znaleźć się w rezultacie. Z kolei wskazanie, że kod wypisze cały adres e-mail jest błędne, ponieważ pętla jest zaprojektowana tak, aby zakończyć działanie przed osiągnięciem znaku '@', więc taki wynik nie jest możliwy. Ostatnia niepoprawna odpowiedź, sugerująca, że kod wypisze samą nazwę domeny, jest również myląca. W kodzie nie ma logiki, która pozwalałaby na wyodrębnienie części po znaku '@'; zamiast tego pętla przerywa działanie, gdy osiągnie ten znak. Jest to kluczowe, aby zrozumieć, że kod nie ma mechanizmu do analizy lub rozdzielania adresu e-mail po znaku '@'. Wszystkie te odpowiedzi pokazują niezrozumienie, jak działają operacje na ciągach w PHP oraz logikę pętli, która w kontekście tego fragmentu kodu jest fundamentalna dla uzyskania prawidłowego wyniku.
Pytanie 5
W języku PHP, aby nawiązać połączenie z bazą danych MySQL za pomocą biblioteki mysqli, wykorzystując podany kod, w miejscu parametru 'c' powinno się wpisać
$a = new mysqli('b', 'c', 'd', 'e')
A. lokalizację serwera bazy danych
B. nazwę użytkownika
C. nazwę bazy danych
D. hasło użytkownika
Aby poprawnie korzystać z biblioteki mysqli w PHP konieczne jest zrozumienie kolejności i znaczenia parametrów używanych do nawiązywania połączenia z bazą danych MySQL. Pierwszym parametrem w funkcji mysqli_connect lub konstruktorze klasy mysqli jest lokalizacja serwera bazy danych. Zazwyczaj wartością domyślną jest 'localhost' co oznacza że serwer bazy danych działa na tej samej maszynie co serwer PHP. Błędne przypisywanie innej wartości w tym miejscu może prowadzić do problemów z połączeniem jeśli serwer bazy danych jest w rzeczywistości lokalny. Drugim parametrem jest nazwa użytkownika która jest niezbędna do autoryzacji dostępu do bazy danych. Często stosowanym błędem jest użycie niewłaściwego użytkownika co może skutkować odmową dostępu do bazy. Trzecim jest hasło które powinno być silne i dobrze zabezpieczone aby zapobiec nieautoryzowanemu dostępowi. Błędne przypisanie tego parametru może skutkować podatnością na ataki. Czwartym parametrem jest nazwa bazy danych do której zamierzamy się połączyć. Błędne podanie tej wartości może powodować że operacje bazy danych będą wykonywane na niewłaściwej bazie co może mieć katastrofalne skutki dla danych. Zrozumienie i poprawne przypisanie tych wartości jest kluczowe w kontekście bezpieczeństwa i stabilności aplikacji webowych i często jest elementem dobrych praktyk w programowaniu PHP. Również zrozumienie tego w kontekście skalowalności i zarządzania środowiskami produkcyjnymi jest istotne aby uniknąć problemów związanych z konfiguracją na różnych etapach rozwoju aplikacji. Właściwe zarządzanie tymi parametrami często wiąże się z używaniem plików konfiguracyjnych co pozwala na łatwiejsze zarządzanie i większą elastyczność w kontekście różnych środowisk programistycznych i produkcyjnych. Poprawne zrozumienie tego mechanizmu jest kluczowe dla tworzenia bezpiecznych i stabilnych aplikacji webowych.
Pytanie 6
Poniższe zapytanie zwróci
SELECTCOUNT(cena) FROMuslugi;
A. wszystkie wartości cen usług w tabeli
B. łączną wartość cen usług w tabeli
C. liczbę wszystkich cen usług w tabeli
D. średnią wartość cen usług w tabeli
Zapytanie SQL "SELECT COUNT(cena) FROM uslugi;" jest skonstruowane w taki sposób, że używa funkcji agregującej COUNT, która zlicza liczbę niepustych wartości w kolumnie "cena" w tabeli "uslugi". Oznacza to, że wynik tego zapytania to liczba wierszy, w których kolumna "cena" nie jest pusta. Używanie funkcji COUNT jest standardową praktyką w SQL, gdy chcemy uzyskać ilość rekordów spełniających określone kryteria. W kontekście analizy danych, zrozumienie tego typu zapytań jest kluczowe, ponieważ pozwala na efektywne zbieranie statystyk, które mogą być później wykorzystane do podejmowania decyzji biznesowych. Na przykład, jeśli firma prowadzi usługi i chce wiedzieć, ile z nich ma przypisaną cenę, to to zapytanie dostarczy tej informacji. Warto także zwrócić uwagę, że funkcja COUNT jest często używana w połączeniu z innymi funkcjami agregującymi, takimi jak SUM czy AVG, w celu uzyskania bardziej kompleksowego obrazu danych.
Pytanie 7
Polecenie DBCC CHECKDB ('sklepAGD', Repair_fast) w systemie MS SQL Server
A. sprawdzi spójność konkretnej tabeli i naprawi uszkodzone dane
B. zweryfikuje spójność danej tabeli
C. sprawdzi spójność bazy danych i naprawi uszkodzone indeksy
D. przeprowadzi kontrolę spójności bazy danych i wykona kopię zapasową
Odpowiedzi, które stwierdzają, że polecenie DBCC CHECKDB sprawdza spójność określonej tabeli, są wynikiem nieporozumienia dotyczącego funkcji tego narzędzia. DBCC CHECKDB działa na poziomie bazy danych, a nie pojedynczych tabel, co oznacza, że jego celem jest ocena integralności całej struktury bazy danych. Przykładowo, niektóre użytkownicy mogą mylić CHECKDB z poleceniem CHECKTABLE, które rzeczywiście sprawdza spójność pojedynczych tabel. Inna błędna koncepcja występuje w odpowiedziach sugerujących, że polecenie wykonuje kopię bezpieczeństwa – w rzeczywistości DBCC CHECKDB nie tworzy kopii zapasowych, a jego celem jest identyfikacja problemów, a nie ich rozwiązanie poprzez archiwizację danych. Warto także zaznaczyć, że chociaż DBCC CHECKDB może naprawić uszkodzone indeksy, nie jest to jego jedyny zakres działania, co czyni błędnym ograniczenie jego funkcjonalności tylko do tego aspektu. Typowe błędy myślowe obejmują także nieznajomość roli, jaką odgrywają indeksy w bazach danych oraz ich wpływu na wydajność. Właściwe zrozumienie działania DBCC CHECKDB i jego opcji naprawczych jest kluczowe dla skutecznego zarządzania bazą danych i zapewnienia jej stabilności.
Pytanie 8
Rekordy do raportu mogą pochodzić z
A. innego raportu
B. tabeli
C. zapytania INSERT INTO
D. makropolecenia
Tabela stanowi fundamentalne źródło danych w kontekście raportowania, ponieważ przechowuje zorganizowane informacje w formie wierszy i kolumn. W praktyce, raporty często opierają się na danych zgromadzonych w tabelach, które są częścią bazy danych. Dzięki strukturze tabeli, możliwe jest łatwe filtrowanie, sortowanie i agregowanie danych, co jest kluczowe w procesie tworzenia raportów. Na przykład, w systemach CRM, dane o klientach są przechowywane w tabeli, co pozwala na wygenerowanie raportów dotyczących sprzedaży, aktywności klientów czy trendów rynkowych. W kontekście standardów branżowych, stosowanie tabel w relacyjnych bazach danych jest nie tylko powszechne, ale również zgodne z najlepszymi praktykami, które zalecają utrzymywanie danych w znormalizowanej formie, aby minimalizować redundancję i ułatwiać zarządzanie danymi. Dodatkowo, w przypadku tworzenia raportów, można korzystać z języka SQL, aby dynamicznie wydobywać dane z tabel, co zwiększa elastyczność i precyzję raportowania.
Pytanie 9
Do zapisania prostej animacji na stronę internetową można zastosować format
A. JPG
B. CDR
C. GIF
D. PNG
JPG, czyli Joint Photographic Experts Group, to format plików graficznych, który jest powszechnie stosowany do zdjęć i obrazów o dużej liczbie kolorów. Format ten jest stratny, co oznacza, że podczas kompresji dochodzi do utraty części informacji, co nie jest idealne dla animacji, które wymagają zachowania wielu klatek w płynny sposób. JPG nie obsługuje przezroczystości, co ogranicza jego zastosowanie w kontekście animacji, gdzie istotne jest, aby tło mogło być różne w zależności od miejsca, w którym animacja jest umieszczona. PNG, czyli Portable Network Graphics, to format bezstratny, który obsługuje przezroczystość i jest doskonały do przechowywania statycznych obrazów z dużą ilością szczegółów. Chociaż PNG jest lepszy od JPG w wielu aspektach, nie obsługuje on animacji, co czyni go niewłaściwym wyborem do tworzenia ruchomych obrazów. CDR, natomiast, to format plików używany przez oprogramowanie CorelDRAW, które jest przeznaczone do tworzenia grafiki wektorowej. CDR jest bardziej odpowiedni do projektowania logo, ilustracji oraz innych grafik wymagających edytowalnych elementów wektorowych. Format ten nie jest obsługiwany przez przeglądarki internetowe w taki sposób, jak GIF, co sprawia, że nie nadaje się do zastosowania w animacjach na stronach WWW. W związku z tym, żaden z tych formatów nie jest odpowiedni do tworzenia animacji, co sprawia, że tylko GIF pozostaje właściwym wyborem w tym kontekście.
Pytanie 10
Która metoda JavaScript służy do dodawania nowego elementu na końcu tablicy?
A. pop()
B. push()
C. shift()
D. unshift()
Metoda <code>push()</code> w JavaScript jest odpowiedzialna za dodawanie nowych elementów na końcu tablicy. Jest to jedna z podstawowych metod manipulujących tablicami i jest szeroko stosowana w różnych projektach webowych. Przykładowo, jeśli masz tablicę zawierającą listę produktów w koszyku zakupowym, możesz użyć <code>push()</code>, aby dodać nowy produkt do tej listy. Ta metoda nie tylko dodaje element, ale także zwraca nową długość tablicy, co jest przydatne, gdy chcesz wiedzieć, ile elementów obecnie zawiera tablica. Warto również zauważyć, że <code>push()</code> modyfikuje oryginalną tablicę, co oznacza, że jest to operacja destruktywna. Użycie tej metody jest zgodne z dobrymi praktykami, ponieważ jest ona szybka i efektywna, zwłaszcza gdy potrzebujesz dynamicznie zmieniać zawartość tablicy w trakcie działania aplikacji.
Pytanie 11
W CSS zapis selektora p > i { color: red; } wskazuje, że kolor czerwony zostanie zastosowany do
A. wszystkiego tekstu w znaczniku <p> z wyjątkiem tekstu w znaczniku <i>
B. wszelkiego tekstu w znaczniku <p> lub wszelkiego tekstu w znaczniku <i>
C. wyłącznie tekstu w znaczniku <i>, który znajduje się bezpośrednio wewnątrz znacznika <p>
D. tylko tego tekstu w znaczniku <p>, który ma przypisaną klasę o nazwie i
Zrozumienie selektorów CSS jest kluczowe dla ich poprawnego zastosowania. W przypadku analizy odpowiedzi, które nie są poprawne, istnieją podstawowe błędy w interpretacji selektorów. Wskazanie, że każdy tekst w znaczniku <p> lub <i> miałby być sformatowany, świadczy o mylnym rozumieniu, jak działają selektory CSS. Selekcja całej zawartości <p> lub <i> ignoruje kluczowy element selektora, jakim jest symbol '>', który precyzyjnie definiuje relację między elementami. Z kolei stwierdzenie, że każdy tekst w znaczniku <p> za wyjątkiem tych w znaczniku <i> byłby formatowany, także wprowadza w błąd, ponieważ nie ma to zastosowania do selektora dzieci. W rzeczywistości, forma ta nie wprowadza w życie żadnych reguł CSS i prowadzi do nieporozumień. Pojęcie przypisania klasy w kontekście selektora określającego <i> jest również mylące; klasy są definiowane oddzielnie i nie mają wpływu na znaczniki bezpośrednio. Kluczowe jest, aby w zrozumieniu CSS zwracać uwagę na hierarchię i relacje między elementami, co pozwala na efektywną kontrolę nad stylem prezentacji treści w dokumentach HTML.
Pytanie 12
Do którego akapitu przypisano podaną właściwość stylu CSS? border-radius: 20%;
A. Rys. D
B. Rys. B
C. Rys. A
D. Rys. C
Właściwość border-radius ma specyficzne zastosowanie do zaokrąglania rogów elementów HTML i w tym kontekście inne odpowiedzi jak Rys. A Rys. C i Rys. D nie wykazują cech związanych z tą właściwością. Rys. A ma ostre krawędzie co sugeruje brak użycia zaokrągleń. To pokazuje że border-radius nie został tam zastosowany co jest często spotykanym błędem w przypadku gdy nie rozumie się działania tej właściwości. Rys. C z kolei ma przerywaną linię obramowania co może wskazywać na użycie innej właściwości CSS np. border-style a nie border-radius. Stylizacja taka jest przydatna do wizualnego oddzielenia sekcji ale nie dotyczy bezpośrednio zaokrąglania rogów. Z kolei Rys. D ma efekt cienia co sugeruje raczej użycie właściwości box-shadow niż border-radius. Często myli się te dwie właściwości ponieważ obie wpływają na wygląd ramki jednak działają na zupełnie innych zasadach. Rozpoznanie użycia właściwej właściwości CSS jest kluczowe w projektowaniu intuicyjnych i estetycznych interfejsów co wymaga zrozumienia jak i kiedy każda z nich powinna być zastosowana. Właściwe wykorzystanie border-radius jako elementu stylizacji jest istotnym aspektem profesjonalnego projektowania stron internetowych co wymaga dokładnego zrozumienia jego wpływu na wygląd i funkcjonalność strony.
Pytanie 13
Który z typów plików dźwiękowych oferuje największą kompresję rozmiaru?
A. MP3
B. CD-Audio
C. WAV
D. PCM
Formaty WAV, PCM oraz CD-Audio nie oferują takiej redukcji rozmiaru pliku jak MP3. WAV to format pliku audio, który przechowuje dźwięk w formie nieskompresowanej, co oznacza, że zachowuje on pełną jakość dźwięku, ale skutkuje to dużymi rozmiarami plików. Na przykład, pięciominutowy utwór w formacie WAV może zajmować nawet 50 MB, co jest niepraktyczne dla przechowywania i przesyłania plików w Internecie. PCM (Pulse Code Modulation) to metoda kodowania analogowego sygnału dźwiękowego w formie cyfrowej, która również nie stosuje kompresji, co przekłada się na duże rozmiary plików. PCM używany jest głównie w profesjonalnej produkcji audio, gdzie jakość dźwięku jest kluczowa, ale nie jest to format przyjazny dla użytkowników szukających oszczędności miejsca. Z kolei CD-Audio to standard audio, który również wykorzystuje PCM. Płyty CD przechowują dźwięk w formacie nieskompresowanym, co skutkuje tym, że standardowa płyta CD mieszcząca około 80 minut muzyki zajmuje około 700 MB. Te formaty, choć istotne w różnych dziedzinach audio, nie zapewniają efektywnej kompresji potrzebnej w codziennym użytku, co czyni je mniej praktycznymi w porównaniu do formatu MP3.
Pytanie 14
W kodzie źródłowym zapisanym w języku HTML wskaż błąd walidacji dotyczący tego fragmentu: ```
CSS
Kaskadowe arkusze stylów (ang. Cascading Style Sheets) to język służący ...```
A. Znacznik br nie został poprawnie zamknięty.
B. Nieznany znacznik h6.
C. Znacznik zamykający /b niezgodny z zasadą zagnieżdżania.
D. Znacznik br nie może występować wewnątrz znacznika p.
Rozważmy błędne koncepcje zawarte w innych odpowiedziach. Wskazanie, że znacznik br nie został poprawnie zamknięty, jest niepoprawne, ponieważ znacznik <br> jest samozamykający i nie wymaga dodatkowego znacznika zamykającego. Często błędem jest próba zamknięcia takich znaczników, co prowadzi do niepotrzebnego zamieszania w kodzie. Dodatkowo, stwierdzenie, że znacznik br nie może występować wewnątrz znacznika p, jest nieprawidłowe. Zgodnie ze standardami HTML, znacznik <br> jest dozwolony wewnątrz <p> i służy do wprowadzenia przerwy linii. Wreszcie, znacznik <h6> jest prawidłowym znacznikiem HTML i jego użycie nie stanowi błędu. Pomyłka ta wynika prawdopodobnie z niepełnej znajomości dostępnych znaczników HTML. Dlatego zawsze warto poszerzać swoją wiedzę na ten temat i regularnie odnosić się do specyfikacji HTML.
Pytanie 15
Zamieszczony kod HTML formularza zostanie wyświetlony przez przeglądarkę w sposób:
Dokładnie tak powinien wyglądać ten formularz! Zwróć uwagę, jak HTML interpretuje znaczniki <br> – one wymuszają przejście do nowej linii, więc w kodzie wyjściowym każda sekcja obowiązków pojawi się osobno, pod sobą. To, że jeden z checkboxów ma atrybuty disabled oraz checked, powoduje, że jest domyślnie zaznaczony, ale nie można go odznaczyć ani zaznaczyć ponownie – to ważny niuans, bo czasem zapomina się, że disabled nie oznacza tylko „wyszarzony”, ale też „nie bierz udziału w wysyłaniu formularza”. Takie wykorzystanie checkboxów jest powszechne, szczególnie jeśli chcesz pokazać użytkownikowi pewne stałe informacje (np. obowiązek, którego nie można uniknąć). Z mojego doświadczenia, bardzo często w praktycznych projektach „disabled” stosuje się np. przy wymaganych oświadczeniach, gdzie użytkownik ma tylko do wglądu informację, że coś już jest włączone i nie może tego zmienić. No i jeszcze – checked przy pisaniu kodu powoduje, że checkbox jest domyślnie zaznaczony, co jest zgodne z kodem źródłowym. Same nazwy pól (czyli atrybuty name i value) zostaną wysłane do serwera tylko dla tych pól, które nie są disabled i użytkownik je zaznaczył. To też jest bardzo praktyczna rzecz, bo pozwala precyzyjnie sterować tym, co trafia do backendu. Moim zdaniem taka forma zapisu formularza to dobry punkt wyjścia do dalszej rozbudowy – łatwo dodać tutaj walidację, obsługę JavaScript czy zastosować style CSS. Trzymanie się tej składni ułatwia też potem pracę zespołową, bo jest czytelna i zgodna z oczekiwaniami innych programistów. Podsumowując, wybrałeś opcję najbliższą temu, co wyświetli przeglądarka na bazie danego kodu HTML – i to jest podejście zgodne ze standardami, doceniane w branży.
Pytanie 16
Oprogramowaniem typowym do obróbki grafiki wektorowej jest
A. Paint
B. Audacity
C. Inkscape
D. Brasero
Inkscape to profesjonalne oprogramowanie do edycji grafiki wektorowej, które jest szeroko stosowane przez projektantów i artystów. Program ten umożliwia tworzenie i edytowanie grafiki wektorowej, co oznacza, że obrazy są zbudowane z linii i kształtów, które można skalować bez utraty jakości. Inkscape obsługuje popularne formaty plików wektorowych, takie jak SVG (Scalable Vector Graphics), a także pozwala na eksport do różnych formatów rastrowych. Praktyczne zastosowania Inkscape obejmują projektowanie logo, ilustracji, infografik oraz elementów interfejsu użytkownika. Biorąc pod uwagę standardy branżowe, Inkscape wspiera wiele narzędzi i funkcji, takich jak warstwy, filtry, gradienty oraz teksty, co czyni go wszechstronnym narzędziem w rękach profesjonalnych grafików. Dodatkowo, dzięki aktywnej społeczności, użytkownicy mogą korzystać z licznych dodatków i zasobów, co zwiększa funkcjonalność programu i pozwala na dostosowanie go do specyficznych potrzeb projektowych.
Pytanie 17
W tabeli podzespoly należy zaktualizować wartość pola URL na "toshiba.pl" dla wszystkich wierszy, gdzie producent to TOSHIBA. W SQL zapis tej modyfikacji będzie wyglądać następująco:
A. UPDATE podzespoly SET URL = 'toshiba.pl'
B. UPDATE podzespoly SET URL = 'toshiba.pl' WHERE producent = 'TOSHIBA';
C. UPDATE podzespoly.producent = 'TOSHIBA' SET URL = 'toshiba.pl';
D. UPDATE producent = 'TOSHIBA' SET URL = 'toshiba.pl';
Wszystkie zaproponowane odpowiedzi, z wyjątkiem pierwszej, są błędne z kilku powodów. Po pierwsze, w drugiej odpowiedzi próbujesz ustawić wartość 'TOSHIBA' dla producenta, co jest niewłaściwe, ponieważ nie określasz, na jakiej tabeli to ma być wykonane. W SQL, składnia UPDATE wymaga wskazania tabeli przed wskazaniem, co ma być zmienione. Ponadto, nie może być tak, że producent jest aktualizowany bez kontekstu tabeli, w której się znajduje. W trzeciej odpowiedzi brakuje klauzuli WHERE, co oznacza, że jeśli komenda zostanie wykonana, to URL dla wszystkich rekordów w tabeli 'podzespoly' zostanie zmieniony na 'toshiba.pl', co jest niepożądane w przypadku chęci aktualizacji tylko niektórych rekordów. Czwarta odpowiedź również jest błędna przez to, że próbuje ustawić producenta jako parametr w kontekście polecenia UPDATE, co nie ma sensu w SQL. Kluczowe znaczenie ma właściwe zrozumienie struktury zapytań SQL oraz ich składni, aby uniknąć typowych problemów związanych z modyfikacją danych. W pracy z bazami danych istotne jest również, by zawsze testować zapytania na mniejszych zbiorach danych lub w środowiskach testowych przed ich wdrożeniem w produkcji, aby zminimalizować ryzyko błędów i utraty danych. Zrozumienie tych elementów jest kluczowe dla poprawnego zarządzania bazami danych.
Pytanie 18
W edytorze grafiki wektorowej zbudowano kształt, który składa się z dwóch figur: trójkąta oraz koła. Aby uzyskać ten kształt, po narysowaniu figur i ich odpowiednim ustawieniu, trzeba użyć funkcji
A. różnicy
B. wykluczenia
C. sumy
D. rozdzielenia
Różnica, rozdzielenie i wykluczenie to operacje, które manipulują kształtami na różne sposoby, ale nie łączą ich w jeden obiekt. Różnica polega na tym, że usuwa się część jednego kształtu z drugiego, tworząc negatyw. Jest to przydatne, gdy trzeba mieć otwory lub przestrzenie w złożonym projekcie, ale nie działa, gdy chcemy połączyć kształty. Rozdzielenie to odseparowanie elementów ścieżki, co może być przydatne w bardziej zaawansowanej edycji, bo pozwala na manipulowanie każdą częścią niezależnie, ale to nie tworzy nowego, połączonego kształtu. Wykluczenie z kolei odnosi się do działania Boolowskiego, które tworzy kształt jako zewnętrzną obwiednię dwóch przecinających się elementów, bez obszarów wspólnych, co jest totalnym przeciwieństwem sumy. Czasem można się w tym pogubić, myląc podobnie brzmiące komendy lub zakładając, że wszystkie narzędzia do łączenia figur działają tak samo. Zrozumienie tych różnic jest ważne, żeby skutecznie korzystać z narzędzi graficznych i mieć dobrej jakości projekty, szczególnie gdy chodzi o profesjonalny druk czy publikacje, gdzie precyzja i czytelność są kluczowe.
Pytanie 19
Jakie jest poprawne zapisanie tagu HTML?
<a href="#hobby">przejdź</a>
A. jest błędny, użyto niewłaściwego znaku # w atrybucie href
B. jest prawidłowy, po kliknięciu w odnośnik otworzy się strona pod adresem "hobby"
C. jest błędny, w atrybucie href powinien być podany adres URL
D. jest poprawny, po kliknięciu w odnośnik strona zostanie przewinięta do elementu o nazwie "hobby"
W znaczniku HTML a z atrybutem href='#hobby' zastosowano tzw. kotwicę fragmentu strony. Jest to popularna technika używana do bezpośredniego przenoszenia użytkownika do określonej części strony internetowej. Znak hash (#) wskazuje, że link odwołuje się do elementu o identyfikatorze hobby w obrębie tej samej strony. Tego rodzaju odnośniki są szeroko stosowane w długich dokumentach gdzie szybka nawigacja między sekcjami poprawia doświadczenie użytkownika. Aby kod działał poprawnie na stronie musi istnieć element z atrybutem id='hobby'. To działanie jest zgodne ze standardami HTML i jest zalecane w projektowaniu dostępnych i przyjaznych dla użytkownika aplikacji internetowych. Warto także pamiętać o stosowaniu opisowych identyfikatorów co ułatwia czytelność kodu i jego późniejsze utrzymanie. Praktyka ta jest zgodna z najlepszymi praktykami w zakresie użyteczności i dostępności stron internetowych co może również wpłynąć pozytywnie na SEO poprzez poprawę struktury strony.
Pytanie 20
Aby grupować obszary na poziomie bloków, które będą stylizowane za pomocą znacznika: należy wykorzystać
A. <span>
B. <div>
C. <param>
D. <p>
Znaczniki <p>, <param> i <span> mają różne funkcje, ale nie nadają się do grupowania elementów w poziomie bloków. Element <p> jest używany głównie do akapitów tekstu, więc nie można go wykorzystać do organizowania innych rzeczy jak obrazy czy formularze. To znaczy, że nie sprawdzi się w bardziej złożonych strukturach, gdzie potrzebujesz elastyczności i różnych typów treści. Z <span> jest podobnie, bo on grupuje tekst w obrębie bloku, ale działa w linii, więc nie tworzy nowych wierszy ani nie zmienia układu. A <param> jest do osadzania obiektów, jak wideo, więc nie ma tu nic wspólnego z grupowaniem treści. Przypisywanie tych funkcji tym znacznikom to błąd, bo każdy z nich ma swoje konkretne zastosowanie, które musisz znać, żeby dobrze projektować strony zgodnie z nowoczesnymi standardami.
Pytanie 21
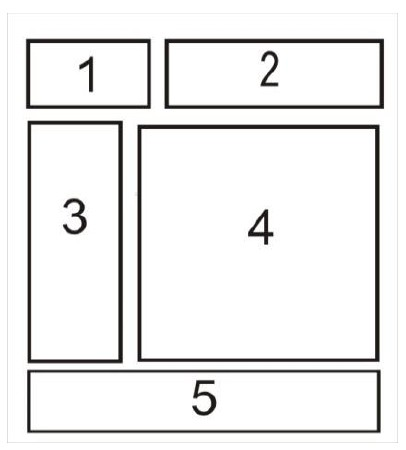
Na ilustracji przedstawiono schemat rozmieszczenia elementów na stronie WWW. W której z jej sekcji zazwyczaj znajduje się stopka strony?
A. 2
B. 5
C. 4
D. 1
Pozycje 1 2 3 i 4 w schemacie rozmieszczenia bloków na stronie WWW nie są odpowiednie do umieszczenia stopki strony z kilku powodów związanych z zasadami projektowania interfejsów użytkownika. W tradycyjnym i intuicyjnym układzie strony internetowej stopka znajduje się na samym dole strony ponieważ jest to miejsce gdzie użytkownicy spodziewają się znaleźć długoterminowe informacje takie jak kontakt polityka prywatności czy prawa autorskie. Umieszczenie stopki w miejscach oznaczonych numerami 1 lub 2 sugeruje że pełniłaby ona rolę nagłówka lub sekcji nawigacyjnej co nie pokrywa się z jej podstawowym przeznaczeniem. Blok 3 z boku strony mógłby być mylony z panelem bocznym który często zawiera treści dodatkowe lub reklamy a nie kluczowe elementy informacyjne jakie znajdują się w stopce. Blok 4 z kolei zwykle przeznaczony jest na główną treść strony przez co jego użycie dla stopki mogłoby zaburzyć przejrzystość przekazu. Przestrzeganie tych zasad jest kluczowe dla stworzenia strony intuicyjnej i zgodnej z oczekiwaniami użytkowników co wpływa na pozytywne ich doświadczenie z korzystania z serwisu. Poprawne rozmieszczenie elementów zgodnie z ich funkcją na stronie jest podstawą udanego projektu UX.
Pytanie 22
Została stworzona baza danych z tabelą podzespoły, która zawiera pola: model, producent, typ, cena. Aby uzyskać listę wszystkich modeli pamięci RAM od firmy Kingston uporządkowanych od najniższej do najwyższej ceny, należałoby użyć kwerendy:
A. SELECT model FROM podzespoły WHERE typ='RAM' AND producent='Kingston' ORDER BY cena DESC
B. SELECT model FROM producent WHERE typ='RAM' OR producent='Kingston' ORDER BY podzespoły ASC
C. SELECT model FROM podzespoły WHERE typ='RAM' AND producent='Kingston' ORDER BY cena ASC
D. SELECT model FROM podzespoły WHERE typ='RAM' OR producent='Kingston' ORDER BY cena DESC
Analizując niepoprawne odpowiedzi, można zauważyć kilka istotnych błędów koncepcyjnych, które prowadzą do błędnych wyników. W przypadku pierwszej z błędnych kwerend, użycie klauzuli ORDER BY cena DESC sprawia, że wyniki są sortowane od najdroższej do najtańszej, co jest sprzeczne z wymaganiem przedstawienia modeli w porządku rosnącym. Problem ten często wynika z błędnego zrozumienia celu sortowania, co może prowadzić do frustracji użytkowników poszukujących najkorzystniejszych cen. W innej z błędnych odpowiedzi, klauzula WHERE wykorzystuje operator OR zamiast AND, co skutkuje zwróceniem modeli RAM od różnych producentów, co jest niewłaściwe w kontekście zadania, które wymaga danych tylko od producenta Kingston. Ponadto, ostatnia odpowiedź zawiera również błąd w odniesieniu do źródła danych, wskazując na tabelę 'producent' zamiast 'podzespoły'. W SQL kluczowe jest zrozumienie struktury danych oraz logiczne formułowanie zapytań, aby uniknąć nieścisłości. Błędy te mogą wynikać z mylnego założenia, że każda zmiana w zapytaniu nie wpływa na jego integralność i wynik, co jest niebezpiecznym podejściem w praktyce programistycznej.
Pytanie 23
Na stronie www znajduje się formularz, do którego należy zaimplementować następujące funkcje: walidacja: podczas wypełniania formularza w czasie rzeczywistym sprawdzana jest poprawność danych, oraz przesyłanie danych: po wypełnieniu formularza i jego zatwierdzeniu informacje są przesyłane do bazy danych na serwerze. Aby wprowadzić tę funkcjonalność w najprostszy sposób, trzeba zapisać
A. walidację i przesyłanie danych w języku JavaScript
B. walidację w języku JavaScript, a przesyłanie danych w skrypcie PHP
C. walidację i przesyłanie danych w języku PHP
D. walidację w skrypcie PHP, a przesyłanie danych w JavaScript
Mówiąc szczerze, podejście, które zakłada walidację i przesyłanie danych tylko w PHP, to nie za bardzo dobry pomysł. Dlaczego? Bo każde weryfikowanie danych po stronie serwera wymaga przesyłania ich tam, co powoduje zbędne obciążenie. To z kolei może spowalniać interakcję z użytkownikiem, co jest frustrujące, zwłaszcza w przypadku większych formularzy. A walidacja w PHP i przesyłanie w JavaScript? Znowu nie jest to najlepsze rozwiązanie. Walidacja po stronie serwera nie jest natychmiastowa, więc użytkownik może czekać, co zazwyczaj nie jest fajne. Gdy ktoś weźmie niepoprawne dane, to musi czekać na odpowiedź serwera i to jest czasochłonne. Najlepiej łączyć walidację w JavaScript, bo to poprawia interakcję, a wysyłanie danych do serwera robić w PHP, bo on dba o bezpieczeństwo i kontakt z bazą danych. Takie rozdysponowanie zadań sprawia, że wszystko chodzi sprawnie i łatwiej to potem rozwijać, co jest zgodne z aktualnymi standardami.
Pytanie 24
Efekt przedstawiony w filmie powinien być zdefiniowany w selektorze
A. tr:hover { background-color: Pink; }
B. tr:active { background-color: Pink; }
C. tr { background-color: Pink; }
D. td, th { background-color: Pink; }
W tym zadaniu chodzi o zrozumienie, jak działają selektory CSS oraz pseudo-klasy odpowiedzialne za interakcję z użytkownikiem. Jeśli efekt ma pojawiać się tylko wtedy, gdy użytkownik najedzie myszką na wiersz tabeli, to zwykłe ustawienie background-color bez pseudo-klasy nie spełni tego warunku. Deklaracja tr { background-color: Pink; } oznaczałaby, że wszystkie wiersze tabeli są cały czas różowe, niezależnie od tego, czy ktoś na nie najedzie, czy nie. To jest po prostu styl statyczny, bez żadnej reakcji na zdarzenia. Podobnie zapis td, th { background-color: Pink; } ustawia tło dla wszystkich komórek tabeli (zarówno nagłówkowych th, jak i zwykłych td) w sposób stały. Moim zdaniem to dość częsty błąd: ktoś kojarzy tabelę z komórkami i intuicyjnie styluje td/th, ale zapomina, że w pytaniu chodzi o efekt dynamiczny „po najechaniu”. W rezultacie otrzymujemy tabelę pokolorowaną na stałe, bez jakiejkolwiek interakcji, co jest sprzeczne z założeniem zadania i z typowym zachowaniem tabel w nowoczesnych interfejsach. Ciekawsza jest kwestia selektora tr:active { background-color: Pink; }. Pseudo-klasa :active oznacza element w momencie „aktywacji”, czyli najczęściej w chwili klikania (przytrzymania przycisku myszy). Efekt trwa bardzo krótko, tylko w czasie samego kliknięcia. To zupełnie inny scenariusz niż wygodne podświetlenie wiersza, które ma się utrzymywać, dopóki kursor jest nad elementem. Użycie :active prowadzi do efektu, który miga na ułamek sekundy i z punktu widzenia ergonomii jest praktycznie bezużyteczny w kontekście podświetlania wierszy. Typowy błąd myślowy przy takich pytaniach polega na myleniu różnych pseudo-klas: :hover, :active, :focus. W webdevie przyjęło się, że :hover służy do reakcji na najechanie myszką, :active do krótkiej reakcji na kliknięcie, a :focus do zaznaczenia elementu, który ma aktualnie fokus klawiatury. Standardy CSS i dobre praktyki projektowania interfejsów jasno wskazują, że do efektu „podświetl wiersz, gdy nad nim jestem” należy użyć właśnie :hover na odpowiednim elemencie, czyli w tym przypadku tr. Wszystkie pozostałe odpowiedzi ignorują tę zasadę albo stosują nie tę pseudo-klasę, co trzeba, przez co nie odzwierciedlają poprawnie zachowania pokazanego w materiale wideo.
A. odebrane uprawnienia usuwania i modyfikowania danych w tabeli pracownicy
B. przydzielone uprawnienia do usuwania i aktualizowania danych w tabeli pracownicy
C. odebrane uprawnienia usuwania i dodawania rekordów w tabeli pracownicy
D. przydzielone uprawnienia do wszelkiej zmiany struktury tabeli pracownicy
Wszystkie niepoprawne odpowiedzi dotyczą różnych aspektów zarządzania uprawnieniami w MySQL, ale nie odzwierciedlają skutków działania polecenia REVOKE. W pierwszej z nieprawidłowych odpowiedzi stwierdza się, że użytkownik otrzymuje prawa do usuwania i aktualizowania danych w tabeli 'pracownicy'. Jest to nieprawda, ponieważ komenda REVOKE ma na celu odebranie, a nie przydzielenie jakichkolwiek uprawnień. Kolejna odpowiedź sugeruje, że użytkownik traci prawa do usuwania i dodawania rekordów w tabeli. Chociaż uprawnienie do usuwania jest słuszne, dodawanie rekordów (INSERT) nie zostało wymienione w poleceniu REVOKE, więc ta odpowiedź jest myląca. Ostatnia niepoprawna opcja wskazuje, że użytkownik zyskuje prawa do zmiany struktury tabeli 'pracownicy'. W rzeczywistości REVOKE nie ma nic wspólnego z uprawnieniami związanymi ze strukturą tabeli, takimi jak ALTER czy CREATE. Właściwe zrozumienie mechanizmów zarządzania uprawnieniami jest kluczowe dla zapewnienia bezpieczeństwa danych oraz skutecznego zarządzania bazą danych w MySQL.
Pytanie 26
Jakie polecenie należy wykorzystać, aby przypisać użytkownikowi uprawnienia do tabel w bazie danych?
A. GRANT
B. SELECT
C. REVOKE
D. CREATE
Odpowiedzi SELECT, CREATE i REVOKE mogą wydawać się związane z zarządzaniem dostępem do bazy danych, ale żadna z nich nie jest prawidłowym sposobem na nadanie uprawnień. SELECT to polecenie wykorzystywane do odczytywania danych z tabeli, a nie do nadawania uprawnień. Użytkownik, który nie ma odpowiednich uprawnień, nie będzie w stanie wykonać SELECT, ale to polecenie nie przyznaje tych uprawnień. CREATE z kolei służy do tworzenia nowych obiektów w bazie danych, takich jak tabele czy bazy danych, i również nie ma związku z zarządzaniem uprawnieniami. REVOKE to polecenie, które służy do odbierania wcześniej nadanych uprawnień, co oznacza, że jego funkcjonalność jest odwrotnością GRANT. Niezrozumienie tych podstawowych różnic może prowadzić do błędów w zarządzaniu dostępem do zasobów bazy danych. Kluczowe jest, aby użytkownicy mieli świadomość, jak te polecenia działają i jakie mają zastosowanie, by unikać sytuacji, w których nieodpowiednie uprawnienia są przyznawane lub odbierane, co może wpłynąć na bezpieczeństwo oraz integralność danych.
Pytanie 27
Jakie obiekty w bazie danych służą do podsumowywania, prezentacji oraz drukowania danych?
A. zapytanie
B. formularz
C. raport
D. zestawienie
Zapytanie, formularz i zestawienie również są ważnymi elementami pracy z bazami danych, jednak żaden z tych obiektów nie spełnia wszystkich funkcji przypisywanych raportom. Zapytanie to instrukcja w języku zapytań, najczęściej SQL, która służy do pobierania danych z bazy danych. Choć zapytania mogą generować dane do późniejszego wykorzystania w raportach, same w sobie nie są narzędziem służącym do ich prezentacji ani podsumowywania. Formularz natomiast to struktura, która umożliwia użytkownikom wprowadzanie danych do bazy danych. Używa się go głównie do zbierania informacji, ale nie do ich analizy czy podsumowywania w formie raportów. Zestawienie to termin, który odnosi się do ogólnego podsumowania danych, ale również nie oferuje tak zaawansowanej i zorganizowanej prezentacji jak raport. Typowym błędem myślowym jest mylenie tych terminów, co może prowadzić do nieporozumień przy projektowaniu systemów informacyjnych. Ważne jest, aby zrozumieć, że każdy z tych elementów pełni inną rolę w zarządzaniu danymi. Aby poprawnie wykorzystać potencjał baz danych, należy umiejętnie dobierać narzędzia do konkretnego zadania.
Pytanie 28
W języku CSS, aby zdefiniować marginesy zewnętrzne o wartościach: margines górny i dolny 20 px, lewy i prawy 40 px należy użyć kodu
A. margin: 20px 40px 40px 20px;
B. margin: 20px 20px 40px 40px;
C. margin: 40px 20px;
D. margin: 20px 40px;
Problem z tym pytaniem wynika głównie z mylenia kolejności wartości w skróconej notacji margin oraz z intuicyjnego założenia, że pierwsza liczba odnosi się do lewej strony, a druga do prawej. W CSS skrócone zapisy mają bardzo konkretną i stałą semantykę, którą warto sobie poukładać raz, a porządnie. Dwie wartości w margin nie oznaczają lewo/prawo i góra/dół, tylko zawsze: pierwsza – góra i dół, druga – lewo i prawo. Jeśli ktoś wybiera margin: 40px 20px;, to w praktyce ustawia 40px na górze i na dole oraz 20px po lewej i po prawej. To jest dokładne przeciwieństwo tego, co było wymagane w treści pytania. Taki błąd często wynika z myślenia „poziomo”: najpierw lewo-prawo, potem góra-dół, a CSS idzie inną logiką. Kolejne nieporozumienie dotyczy zapisów z czterema wartościami. Wiele osób ma problem z zapamiętaniem kolejności. Standard CSS definiuje to jasno: gdy podajemy cztery liczby, interpretacja idzie zgodnie z ruchem wskazówek zegara, zaczynając od góry: top, right, bottom, left. Czyli margin: 20px 20px 40px 40px; oznacza: góra 20px, prawo 20px, dół 40px, lewo 40px. W pytaniu chcemy: góra 20px, dół 20px, lewo 40px, prawo 40px, więc ten zapis nie spełnia warunku, bo wartości dla prawej strony są inne niż dla lewej, a górna różni się od dolnej. Podobnie margin: 20px 40px 40px 20px; rozwija się do: 20px na górze, 40px po prawej, 40px na dole, 20px po lewej. Tutaj symetria jest odwrotna: góra i lewo mają 20px, a dół i prawo 40px. Z mojego doświadczenia typowy błąd polega na tym, że ktoś próbuje „na czuja” dopasować liczby, zamiast trzymać się sztywnej reguły: 2 wartości – góra/dół oraz lewo/prawo, 4 wartości – góra, prawo, dół, lewo. W efekcie kod może nawet wyglądać sensownie na pierwszy rzut oka, ale przeglądarka zinterpretuje go zupełnie inaczej, niż autor zakładał. Dlatego warto myśleć o margin w kontekście box modelu i specyfikacji, a nie tylko wizualnie. Dobra praktyka jest taka, żeby przy bardziej skomplikowanych odstępach na początku rozpisywać margin-top, margin-right, margin-bottom, margin-left osobno, a dopiero potem, gdy mamy pewność, zamieniać to na skróconą notację. To ogranicza liczbę takich subtelnych, ale uciążliwych pomyłek w layoutach.
Pytanie 29
.format1{
…
}
W CSS określono wspólne style dla pewnej grupy elementów. Użycie takich stylów w kodzie HTML odbywa się za pomocą atrybutu:
A. div = "format1"
B. style = "format1"
C. id = "format1"
D. class = "format1"
Użycie atrybutu class w języku HTML do formatowania grupy znaczników jest zgodne z najlepszymi praktykami web developmentu. Atrybut class pozwala na zastosowanie tej samej definicji stylu CSS do wielu elementów, co jest efektywne i utrzymuje porządek w kodzie. Umożliwia to również łatwą zmianę wyglądu strony poprzez modyfikację tylko jednej definicji CSS zamiast ręcznego edytowania stylów każdego z elementów z osobna. Dzięki takiemu podejściu, programista może szybko aktualizować wygląd całej strony lub jej części bez ryzyka, że pominięte zostaną pojedyncze elementy. Ponadto użycie klas jest zgodne ze standardami W3C, co zapewnia kompatybilność i poprawne renderowanie w różnych przeglądarkach. Praktycznym przykładem zastosowania jest stronie, gdzie wszystkie elementy z klasą .format1 będą miały jednolity wygląd, na przykład wszystkie przyciski na stronie mogą mieć jednakowy kolor i styl. Pozwala to na tworzenie spójnych interakcji użytkownika i ułatwia przyszłą rozbudowę strony o dodatkowe funkcje.
Pytanie 30
Tabele: Studenci, Zapisy, Zajecia są powiązane relacją. Aby wybrać jedynie nazwiska studentów oraz odpowiadające im idZajecia dla studentów z grupy 15, należy wydać kwerendę
A. SELECT nazwisko, idZajecia FROM Studenci JOIN Zapisy ON Studenci.id = Zapisy.idZajecia WHERE grupa = 15;
B. SELECT nazwisko, idZajecia FROM Studenci INNER JOIN Zapisy ON Studenci.id = Zapisy.idStudenta;
C. SELECT nazwisko, idZajecia FROM Studenci JOIN Zapisy ON Studenci.id = Zapisy.idStudenta WHERE grupa = 15;
D. SELECT nazwisko, idZajecia FROM Studenci INNER JOIN Zapisy WHERE grupa= 15;
Wśród proponowanych rozwiązań pojawiają się charakterystyczne błędy, często spotykane przy pierwszych próbach pracy z relacyjnymi bazami danych. Bardzo łatwo jest pomylić się na etapie łączenia tabel, zwłaszcza gdy nie do końca rozumie się, jak działa klucz główny i obcy w praktyce. Jeden z typowych problemów polega na pominięciu warunku określającego, w jaki sposób tabele mają być połączone – wtedy system bazodanowy tworzy tzw. iloczyn kartezjański, czyli paruje każdy rekord z jednej tabeli z każdym z drugiej, co zwykle daje absurdalnie dużo wyników i nie ma nic wspólnego z rzeczywistością. Popularny błąd to też użycie niewłaściwych pól do łączenia – np. próba połączenia idStudenta z idZajecia, które są ze sobą kompletnie niepowiązane, bo reprezentują dwa różne byty. Z mojego doświadczenia wynika, że często myli się pole id w tabeli Studenci z polem idZajecia w tabeli Zapisy – to są zupełnie inne klucze i nie mają prawa się zgadzać. Inna pułapka pojawia się, gdy zapomni się o warunku WHERE filtrującym po konkretnej grupie, przez co wynik zawiera dane wszystkich studentów, a nie tylko tych z interesującej nas grupy. Trzeba też pamiętać, że poprawna kolejność oraz jawne stosowanie JOIN z warunkiem ON to nie tylko kwestia składni, ale i wydajności oraz czytelności kodu. Warto mocno utrwalić sobie, że łączenie przez JOIN i jasno określony warunek ON to podstawa dobrej praktyki i niemal zawsze sprawdza się przy pracy z większymi, złożonymi bazami danych – zupełnie inaczej niż domyślne, niejawne łączenia czy łączenie po złych polach.
Pytanie 31
W instrukcji warunkowej w JavaScript powinno się zweryfikować sytuację, w której zmienne a oraz b są większe od zera, przy czym zmienna b jest mniejsza od 100. Taki warunek należy zapisać w następujący sposób:
A. if ( a > 0 && b > 0 || b > 100)
B. if ( a > 0 || b > 0 || b > 100)
C. if ( a > 0 && b > 0 && b < 100)
D. if ( a > 0 || (b > 0 && b < 100))
W analizowanych odpowiedziach pojawia się kilka koncepcji, które nie spełniają wymagań dotyczących sprawdzenia warunków dla zmiennych a i b. Odpowiedź if ( a > 0 || b > 0 || b > 100) jest błędna, ponieważ użycie operatora OR (||) wskazuje, że wystarczy, aby przynajmniej jeden z warunków był spełniony. Taki zapis wpłynąłby na logikę programu, prowadząc do sytuacji, w której program uznałby, że warunki są spełnione, nawet jeśli b jest większe lub równe 100, co całkowicie ignoruje kluczowy wymóg dotyczący tej zmiennej. W drugiej analizowanej opcji, if ( a > 0 && b > 0 || b > 100), znowu mamy do czynienia z niewłaściwym połączeniem operatorów, które może prowadzić do błędnych wyników. Tu z kolei program będzie mógł uznać warunek za prawdziwy, jeśli b przekroczy 100, nawet jeżeli a i b nie są dodatnie, co narusza zasady logicznego myślenia. Argumenty w if ( a > 0 || (b > 0 && b < 100)) również nie są zgodne z wymaganiami, ponieważ zastosowanie operatora OR sprawia, że program uzna warunek za prawdziwy, jeżeli tylko a jest dodatnie, co nie jest zgodne z zasadą, że obie zmienne powinny spełniać warunki. Przykładowo, w kontekście aplikacji bankowej, takie niepoprawne sprawdzenie mogłoby prowadzić do nieautoryzowanych transakcji, co byłoby poważnym zagrożeniem dla bezpieczeństwa użytkowników.
Pytanie 32
Podaj zapytanie SQL, które tworzy użytkownika sekretarka na localhost z hasłem zaq123
CREATE USER `sekretarka`@`localhost` IDENTIFY "zaq123";
A. CREATE USER 'sekretarka'@'localhost' IDENTIFIED `zaq123`
B. CREATE USER `sekretarka`@`localhost` IDENTIFIED BY 'zaq123'
C. CREATE USER `sekretarka`@`localhost` IDENTIFY "zaq123"
D. CREATE USER `sekretarka`@`localhost` IDENTIFY BY `zaq123`
Użycie nieprawidłowych składni w zapytaniach SQL może prowadzić do nieporozumień i błędów w konfiguracji użytkowników. W przypadku podanych błędnych odpowiedzi, brak użycia frazy 'IDENTIFIED BY' z odpowiednio umieszczonym hasłem w pojedynczych cudzysłowach jest kluczowym błędem. Na przykład, w jednym z przypadków zastosowano słowo 'IDENTIFY', które jest niepoprawne i nie jest częścią składni SQL dla tworzenia użytkowników. Różnice w użyciu pojedynczych cudzysłowów i backticks również mają znaczenie; backticks są używane do oznaczania nazw obiektów w SQL, podczas gdy hasła powinny być otoczone pojedynczymi cudzysłowami. Ponadto, znaki takie jak ` zaq123` w niektórych odpowiedziach sugerują mylne zrozumienie zasad definiowania danych tekstowych w SQL. Niepoprawne podejście do tworzenia użytkowników może skutkować problemami w zakresie bezpieczeństwa, ponieważ niewłaściwie skonfigurowani użytkownicy mogą uzyskiwać nieautoryzowany dostęp do systemów. Właściwe zrozumienie składni SQL oraz terminologii jest kluczowe do skutecznego zarządzania bazami danych i zapewnienia odpowiedniego poziomu ochrony informacji.
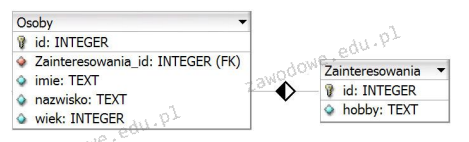
Pytanie 33
Tabele Osoby oraz Zainteresowania są połączone relacją jeden do wielu. Jakie zapytanie SQL należy użyć, aby w oparciu o tę relację poprawnie wyświetlić imiona i odpowiadające im hobby?
A. SELECT imie, hobby FROM Osoby JOIN Zainteresowania ON Osoby.Zainteresowania_id = Zainteresowania.id;
B. SELECT imie, hobby FROM Osoby, Zainteresowania WHERE Osoby.id = Zainteresowania.id;
C. SELECT imie, hobby FROM Osoby, Zainteresowania;
D. SELECT imie, hobby FROM Osoby.Zainteresowania_id = Zainteresowania.id FROM Osoby, Zainteresowania;
Wiele osób mylnie uważa, że można łączyć tabele w SQL bez wyraźnego określenia relacji między nimi. Jednak takie podejście, jak w odpowiedzi numer 2 i 3, prowadzi do niepoprawnych wyników, ponieważ nie definiujemy, w jaki sposób dane z tych tabel mają być łączone. To może skutkować produkcją tzw. iloczynu kartezjańskiego, gdzie każda kolumna z pierwszej tabeli jest łączona z każdą kolumną z drugiej tabeli. W kontekście dużych baz danych takie podejście nie jest skalowalne i powoduje niepotrzebne obciążenie systemu. Odpowiedź numer 4 zakłada istnienie bezpośredniego połączenia między kolumną Osoby.id a Zainteresowania.id, co jest błędnym założeniem, gdyż w analizowanym przypadku tabele są połączone poprzez kolumny Osoby.Zainteresowania_id i Zainteresowania.id. Niepoprawne rozumienie struktury bazy danych prowadzi do błędnych przekonań o relacjach między danymi. Ważne jest, aby zawsze zwracać uwagę na klucze obce, które definiują rzeczywiste połączenia w modelu danych. Dokładne zrozumienie struktury i logiki relacyjnych baz danych jest kluczowe dla pisania efektywnych i poprawnych zapytań SQL. Umiejętność prawidłowego łączenia tabel stanowi fundament dla tworzenia zaawansowanych zapytań, które są niezbędne w profesjonalnym zarządzaniu bazami danych.
Pytanie 34
W poniższym kodzie PHP wykonano operację na bazie danych. Której funkcji należy użyć, aby pobrać liczbę zmienionych w tabeli wierszy?
$zapytanie="UPDATE kadra SET stanowisko='Programista' WHERE id < 10";mysqli_query($db, $zapytanie);
A. mysqli_affected_rows()
B. mysqli_num_rows()
C. mysqli_field_count()
D. mysqli_use_result()
Wybrana odpowiedź jest niestety niepoprawna. Może to wynikać z niezrozumienia różnych funkcji dostępnych w języku PHP do manipulowania danymi w bazach danych MySQL. Funkcja mysqli_field_count() zwraca liczbę pól w wyniku zapytania SELECT, a nie liczbę zmienionych wierszy. Z kolei mysqli_use_result() inicjuje pobieranie wyników zapytania wysłanego do serwera MySQL i nie zwraca informacji o liczbie zmienionych wierszy. Natomiast funkcja mysqli_num_rows() zwraca liczbę wierszy w wyniku zapytania SELECT, a nie liczbę zmienionych wierszy. Do tego celu służy jedynie funkcja mysqli_affected_rows(), która zwraca liczbę wierszy zmienionych, dodanych lub usuniętych przez ostatnie wywołanie funkcji mysqli_query() na serwerze MySQL. Pamiętaj więc, że wybór odpowiedniej funkcji zależy od kontekstu i rodzaju operacji wykonanej na bazie danych.
Pytanie 35
Który zapis jest selektorem pseudoklasy CSS?
A. a:link
B. td.wyroznienie
C. p#wyroznienie
D. body
W tym zadaniu wszystkie odpowiedzi wyglądają jak poprawne selektory CSS, ale tylko jedna z nich jest selektorem pseudoklasy. To dość typowa pułapka: ktoś widzi poprawny składniowo selektor i automatycznie zakłada, że skoro jest „jakiś znak specjalny”, to pewnie chodzi o pseudoklasę. W CSS warto jednak rozróżniać kilka zupełnie różnych mechanizmów: selektor typu, selektor klasy, selektor identyfikatora oraz właśnie pseudoklasy. Zapis „p#wyroznienie” łączy selektor typu z selektorem identyfikatora. Oznacza akapit <p> o konkretnym id="wyroznienie". Znak # w CSS nie ma nic wspólnego z pseudoklasami, tylko jednoznacznie wskazuje na identyfikator elementu. To jest bardzo częste nieporozumienie: część osób myli dwukropek z kratką, bo oba wyglądają jak „specjalne dopiski”. Tymczasem pseudoklasy zawsze używają dwukropka, a identyfikatory – znaku #. „td.wyroznienie” to z kolei połączenie selektora typu z selektorem klasy. Ten zapis wybierze komórki tabeli <td> posiadające class="wyroznienie". Kropka w CSS zawsze oznacza klasę, czyli coś, co definiujemy w atrybucie class w HTML. To zupełnie inny mechanizm niż pseudoklasy, bo klasę nadajemy ręcznie w kodzie HTML, a pseudoklasa opisuje stan lub cechę obliczaną przez przeglądarkę, np. czy element jest pierwszy w swoim rodzicu, czy link jest odwiedzony, czy pole formularza ma fokus. Zapis „body” to najprostszy możliwy selektor typu – wskazuje wszystkie elementy <body> w dokumencie (zwykle jest tylko jeden). Tu w ogóle nie ma żadnego symbolu wskazującego na pseudoklasę, więc traktowanie tego jako pseudoklasy to już zupełne pomieszanie pojęć: to po prostu nazwa elementu HTML. Typowy błąd myślowy przy takich pytaniach polega na tym, że zamiast skupić się na definicji pseudoklasy („selektor z dwukropkiem, opisujący stan”), uczestnik testu szuka odpowiedzi, która „najbardziej wygląda na zaawansowaną”. Tymczasem wszystkie błędne odpowiedzi są zwykłymi, podstawowymi selektorami: typu, klasy i id. Pseudoklasa zawsze ma postać coś:coś_tam, np. a:hover, button:disabled, li:first-child. Jeżeli nie ma dwukropka – to na pewno nie jest pseudoklasa, niezależnie od tego, jak bardzo skomplikowany wygląda zapis.
Pytanie 36
Który z parametrów obiektu graficznego zmieni się po dostosowaniu wartości kanału alfa?
A. Nasycenie kolorów
B. Ostrość krawędzi
C. Kolejność wyświetlania pikseli
D. Przezroczystość
Nasycenie barw odnosi się do intensywności kolorów w obiekcie graficznym. Zmiana wartości kanału alfa, która wpływa jedynie na przezroczystość, nie ma bezpośredniego wpływu na nasycenie kolorów. Przezroczystość nie zmienia tego, jak intensywne lub wyblakłe są kolory, ale raczej to, jak są one postrzegane w kontekście tła. Ostrość krawędzi odnosi się do wyrazistości konturów obiektu graficznego. Zmiana wartości kanału alfa nie wpływa na ostrość krawędzi, ponieważ ta zależy od rozdzielczości obrazu oraz technik renderowania, a nie na poziomie przezroczystości. Kolejność wyświetlania pikseli dotyczy tego, jak elementy graficzne są renderowane na ekranie w kontekście ich nakładania się na siebie. Modyfikacja kanału alfa nie zmienia kolejności wyświetlania pikseli, lecz może wpływać na to, jak obiekty się ze sobą mieszają, co w konsekwencji może wprowadzać wrażenie głębi, ale nie zmienia samej kolejności renderowania. W związku z tym, zmiana kanału alfa oddziałuje wyłącznie na aspekt przezroczystości, nie wpływając na pozostałe wymienione parametry, które są niezależne od tego atrybutu.
Pytanie 37
Jaki wynik pojawi się po wykonaniu zaprezentowanego kodu HTML?
A. Odpowiedź D
B. Odpowiedź B
C. Odpowiedź C
D. Odpowiedź A
W analizie kodu HTML istotne jest zrozumienie struktury zagnieżdżonych list. Błędne odpowiedzi wynikają z niedokładnej interpretacji hierarchii i stylizacji list. Listy uporządkowane oznaczone tagiem ol oraz nieuporządkowane ul są podstawą do strukturalizacji informacji w HTML. Częsty błąd polega na nieuwzględnieniu, jak przeglądarki interpretują zagnieżdżone listy. Element ol z atrybutami type i start zmienia styl numeracji. Wersje z atrybutem type=A zmieniają numerację na literową, a start=4 decyduje o punkcie startowym. Pominięcie tego aspektu prowadzi do błędnych wniosków. Dobre praktyki obejmują klarowność struktury HTML poprzez właściwe użycie tagów i atrybutów, co jest kluczowe dla dostępności i użyteczności stron. Przy projektowaniu, warto pamiętać o spójności formatowania i zgodności z semantyką HTML, co poprawia doświadczenia użytkowników i wydajność SEO. Właściwe zrozumienie i zastosowanie atrybutów list ułatwia zarządzanie złożonymi strukturami na stronach internetowych.
Pytanie 38
Podczas definiowania tabeli produkty należy stworzyć pole cena, które będzie reprezentować wartość produktu. Odpowiedni typ danych dla tego pola to
A. INTEGER(11)
B. ENUM
C. TINYTEXT
D. DECIMAL(10, 2)
Typ DECIMAL(10, 2) jest optymalnym wyborem dla pola reprezentującego cenę produktu w bazie danych. Pozwala on na przechowywanie liczb dziesiętnych z określoną precyzją, co jest kluczowe w kontekście finansowym, gdzie dokładność kwot ma fundamentalne znaczenie. Wartość '10' oznacza maksymalną liczbę cyfr, które mogą zostać zapisane, a '2' definiuje liczbę cyfr po przecinku. Oznacza to, że możemy przechowywać wartości od -99999999.99 do 99999999.99, co jest wystarczające dla większości zastosowań komercyjnych. Użycie tego typu danych zapewnia, że operacje matematyczne, takie jak dodawanie, odejmowanie czy mnożenie cen, będą wykonywane z zachowaniem dokładności. Jest to zgodne z najlepszymi praktykami w projektowaniu baz danych, gdzie unika się typów danych, które mogą prowadzić do utraty precyzji, jak np. FLOAT czy DOUBLE. Przykładowo, w aplikacji e-commerce, gdzie ceny produktów są często wyświetlane z dwoma miejscami po przecinku, typ DECIMAL jest idealnym rozwiązaniem, aby uniknąć błędów w obliczeniach i zapewnić pełną przejrzystość cenową dla użytkowników.
Pytanie 39
Dla strony internetowej stworzono styl, który będzie stosowany tylko do wybranych znaczników, takich jak niektóre nagłówki oraz kilka akapitów. W tej sytuacji, aby przypisać styl do konkretnych znaczników, najodpowiedniejsze będzie użycie
A. identyfikatora
B. pseudoklasy
C. klasy
D. selektora akapitu
Pseudoklasy w CSS są używane do stylizowania elementów w określonym stanie, np. :hover dla zmiany stylu po najechaniu myszą. Nie są odpowiednie do przypisywania unikalnych stylów do konkretnych elementów. Identyfikator w CSS, oznaczany przez #, jest używany do stylizowania jednego unikalnego elementu na stronie. Jego użycie jest ograniczone do jednego elementu, co jest zgodne z zasadą unikalności identyfikatorów w dokumencie HTML. Nie nadaje się do sytuacji, gdy ten sam styl ma być stosowany do wielu elementów, ponieważ zmuszałoby to do definiowania i przypisywania wielu unikalnych identyfikatorów do każdego z nich, co jest przeciwieństwem DRY (Don't Repeat Yourself). Selektor akapitu bezpośrednio odnosi się do wszystkich elementów danego typu, np. p dla wszystkich akapitów. Nie jest on elastyczny, gdy chcemy zastosować styl tylko do niektórych elementów danego typu. Klasy oferują większą elastyczność w zarządzaniu stylami wielu elementów, ponieważ mogą być stosowane do różnych typów elementów w różnych miejscach dokumentu HTML. Ponadto, klasy są bardziej czytelne i ułatwiają utrzymanie kodu, co jest zgodne z najlepszymi praktykami w programowaniu front-endowym. Użycie klas wspiera również lepszą strukturę i modularność kodu CSS, co jest istotne w kontekście pracy zespołowej oraz skalowalności projektu.
Pytanie 40
Według którego parametru oraz dla ilu tabel zostaną zwrócone wiersze na liście w wyniku przedstawionego zapytania?
SELECT * FROM producent, hurtownia, sklep, serwis WHERE producent.nr_id = hurtownia.nr_id AND producent.wyrob_id = serwis.wyrob_id AND hurtownia.nr_id = sklep.nr_id AND sklep.nr_id = serwis.nr_id AND producent.nr_id = 1;
A. Według parametru nr id dla wszystkich tabel.
B. Według parametru wyrób id dla wszystkich tabel.
C. Według parametru nr id wyłącznie dla trzech tabel.
D. Według parametru wyrób Jd wyłącznie dla trzech tabel.
Wybrana odpowiedź jest niepoprawna. Wszystkie tabelki są łączone przez wartość kolumny nr id, a nie konkretnie przez 'wyrób id' lub 'wyrób Jd'. Ważne jest, aby pamiętać, że zapytanie SQL odnosi się do wszystkich tabel, a nie tylko do trzech. W niektórych odpowiedziach może wystąpić błąd, polegający na myśleniu, że zapytanie dotyczy tylko trzech tabel, podczas gdy w rzeczywistości dotyczy ono czterech: producent, hurtownia, sklep i serwis. Ponadto, zrozumienie, jakie konkretne parametry są używane do zwracania wierszy, jest kluczowe dla zrozumienia, jak działa zapytanie. Zrozumienie tego, jakie parametry są używane w zapytaniu SQL, jest kluczowe dla zrozumienia, jakie dane są zwracane i dlaczego. Niewłaściwe zrozumienie tego, jakie parametry są używane w zapytaniu, może prowadzić do niewłaściwego zrozumienia, jakie dane są zwracane i dlaczego. Pamiętaj, że idealnym celem jest nie tylko zrozumienie, jak działa zapytanie, ale także zrozumienie, dlaczego zwraca konkretne dane i jak te dane są związane z naszymi potrzebami programistycznymi.
Odtwarzaj przebieg egzaminu krok po kroku i ucz się na własnych błędach. Widzisz dokładnie, w jakiej kolejności rozwiązywałeś pytania, ile czasu spędziłeś nad każdym z nich i kiedy zmieniałeś odpowiedzi.
Co znajdziesz na stronie przebiegu:
Suwak czasu
Przesuwaj i przeglądaj pytania w kolejności, w jakiej je rozwiązywałeś
Tryb nauki
Włącz, aby zobaczyć poprawne odpowiedzi i wyjaśnienia do pytań
Analiza czasu
Sprawdź, ile czasu spędziłeś nad każdym pytaniem i gdzie traciłeś czas
Monitoring focusu
Widzisz momenty, gdy opuściłeś zakładkę - tak jak widzi to nauczyciel
Strona wykorzystuje pliki cookies do poprawy doświadczenia użytkownika oraz analizy ruchu. Szczegóły
Polityka plików cookies
Czym są pliki cookies?
Cookies to małe pliki tekstowe, które są zapisywane na urządzeniu użytkownika podczas przeglądania stron internetowych. Służą one do zapamiętywania preferencji, śledzenia zachowań użytkowników oraz poprawy funkcjonalności serwisu.
Jakie cookies wykorzystujemy?
Niezbędne cookies - konieczne do prawidłowego działania strony
Funkcjonalne cookies - umożliwiające zapamiętanie wybranych ustawień (np. wybrany motyw)
Analityczne cookies - pozwalające zbierać informacje o sposobie korzystania ze strony
Jak długo przechowujemy cookies?
Pliki cookies wykorzystywane w naszym serwisie mogą być sesyjne (usuwane po zamknięciu przeglądarki) lub stałe (pozostają na urządzeniu przez określony czas).
Jak zarządzać cookies?
Możesz zarządzać ustawieniami plików cookies w swojej przeglądarce internetowej. Większość przeglądarek domyślnie dopuszcza przechowywanie plików cookies, ale możliwe jest również całkowite zablokowanie tych plików lub usunięcie wybranych z nich.