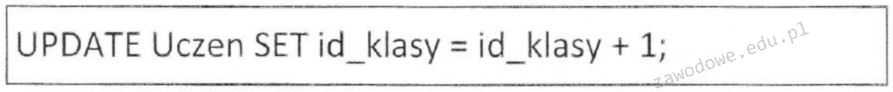Pytanie 1
Jak określa się część strukturalnego języka zapytań, która dotyczy tworzenia zapytań do bazy danych za pomocą polecenia SELECT?
A. SQL DML (ang. Data Manipulation Language)
B. SQL DCL (ang. Data Control Language)
C. SQL DDL (ang. Data Definition Language)
D. SQL DQL (ang. Data Query Language)
Wybór SQL DML, SQL DCL lub SQL DDL jako odpowiedzi na to pytanie wskazuje na nieporozumienie dotyczące funkcji poszczególnych podzbiorów SQL. SQL DML (Data Manipulation Language) odnosi się do poleceń, które modyfikują dane w bazie, takich jak INSERT, UPDATE i DELETE. Myląc te pojęcia, można sądzić, że polecenia te są odpowiednie do pobierania danych, co jest błędne. Z kolei SQL DCL (Data Control Language) służy do zarządzania uprawnieniami użytkowników i kontroli dostępu do danych, co również nie ma związku z formułowaniem zapytań do bazy danych. Na przykład, polecenia GRANT i REVOKE są kluczowe w kontekście DCL, ale nie mają nic wspólnego z wyciąganiem danych. SQL DDL (Data Definition Language) dotyczy definicji struktury bazy danych, czyli tworzenia, modyfikowania i usuwania tabel oraz innych obiektów bazy danych (np. CREATE, ALTER, DROP). Wybór któregokolwiek z tych podzbiorów zamiast DQL wskazuje na brak zrozumienia hierarchii i celów SQL jako całości. Zrozumienie różnic między tymi podzbiorami jest kluczowe dla skutecznego zarządzania danymi i efektywnej pracy z bazami danych. Dobrą praktyką jest zapoznanie się z pełnym zakresem możliwości SQL, aby lepiej wykorzystać jego potencjał w codziennej pracy z danymi.