Pytanie 1
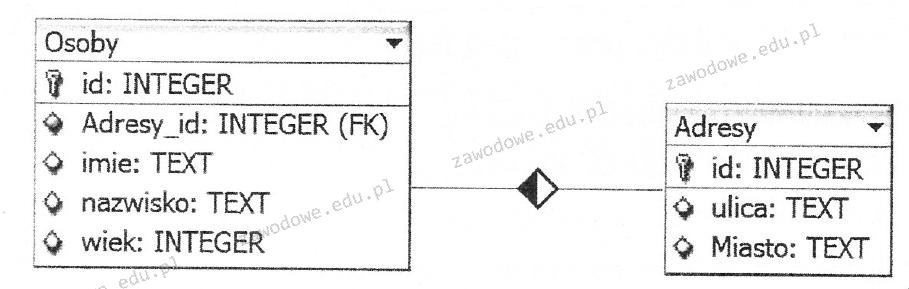
Aby stworzyć relację jeden do wielu, w tabeli po stronie wiele, co należy zdefiniować?
A. klucz podstawowy wskazujący na klucz podstawowy tabeli po stronie jeden
B. klucz sztuczny odnoszący się do kluczy podstawowych obu tabel
C. klucz obcy wskazujący na klucz podstawowy tabeli po stronie jeden
D. klucz obcy wskazujący na klucz obcy tabeli po stronie jeden
W kontekście relacji jeden do wielu w bazach danych, każda z podanych niepoprawnych opcji wprowadza w błąd odnośnie do zasady funkcjonowania kluczy obcych i ich roli w modelowaniu danych. Klucz obcy wskazujący na klucz obcy tabeli po stronie jeden jest konceptualnie błędny, ponieważ klucz obcy zawsze odnosi się do klucza podstawowego innej tabeli, a nie do innego klucza obcego. Taki układ narusza zasady referencyjności i integralności danych, co może prowadzić do trudności w utrzymaniu spójności w bazie. Kolejną niepoprawną opcją jest klucz sztuczny odnoszący się do kluczy podstawowych obu tabel. Klucze sztuczne, choć mogą być użyteczne w pewnych kontekstach, nie powinny być używane jako sposób tworzenia relacji, ponieważ nie odzwierciedlają naturalnych powiązań między danymi. Klucz podstawowy wskazujący na klucz podstawowy tabeli po stronie jeden również jest mylny, ponieważ w relacji jeden do wielu klucz podstawowy tabeli 'jeden' musi być referencjonowany przez klucz obcy w tabeli 'wiele', a nie odwrotnie. Te nieporozumienia mogą prowadzić do błędów projektowych w bazach danych, co w efekcie utrudnia ich rozwój i zarządzanie, szczególnie w dużych systemach, gdzie spójność danych jest kluczowa dla funkcjonowania aplikacji.