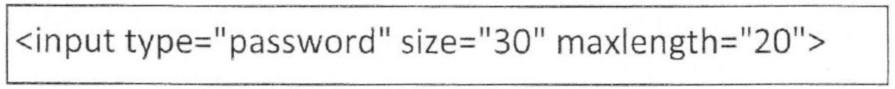Pytanie 1
Celem testów wydajnościowych jest ocena
A. ciągu zdarzeń, w którym prawdopodobieństwo danego zdarzenia zależy tylko od wyniku zdarzenia wcześniejszego
B. zdolności programu do funkcjonowania w sytuacjach, gdy system działa niepoprawnie
C. zdolności programu do funkcjonowania w sytuacjach, gdy sprzęt działa niepoprawnie
D. stopnia, w jakim system lub moduł spełnia wymagania dotyczące wydajności
Analizując pozostałe odpowiedzi, można zauważyć, że żadna z nich nie odnosi się bezpośrednio do istoty testów wydajnościowych. Pierwsza z nich sugeruje, że testy te mają na celu sprawdzenie zdolności oprogramowania do działania w warunkach wadliwej pracy sprzętu. Chociaż testowanie pod kątem awarii sprzętowych jest istotnym elementem inżynierii oprogramowania, to nie jest to kluczowy aspekt testów wydajnościowych. Testy wydajnościowe koncentrują się na ocenie wydajności, a nie na sprawdzaniu reakcji systemu na uszkodzenia sprzętu. Druga odpowiedź dotyczy zdolności oprogramowania do działania w warunkach wadliwej pracy systemu, co także jest ważnym zagadnieniem w kontekście testowania, lecz nie jest to celem testów wydajnościowych. Testowanie odporności i niezawodności systemu jest częścią testowania funkcjonalnego, a nie wydajnościowego. Z kolei ostatnia z propozycji odnosi się do analizy ciągu zdarzeń, w którym prawdopodobieństwo każdego zdarzenia zależy jedynie od wyniku poprzedniego. To zagadnienie dotyczy bardziej teorii prawdopodobieństwa i statystyki, a nie bezpośrednio wydajności oprogramowania. Testy wydajnościowe skupiają się na mierzeniu i optymalizacji parametrów, a nie na analizie statystycznej zdarzeń w kontekście ich prawdopodobieństwa.