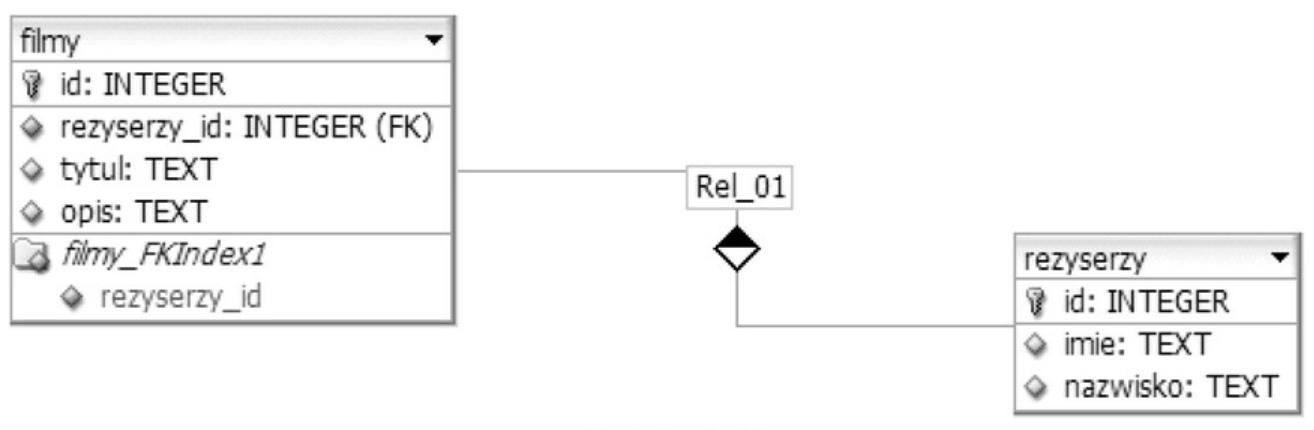
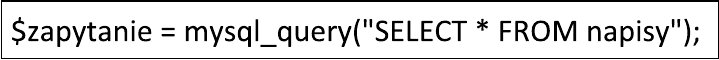Pytanie 1
Zastosowanie klauzuli PRIMARY KEY w poleceniu CREATE TABLE sprawi, że dane pole stanie się
A. kluczem podstawowym
B. kluczem obcym
C. indeksem klucza
D. indeksem unikalnym
Klauzula PRIMARY KEY w instrukcji CREATE TABLE definiuje unikalny identyfikator dla każdej rekord w tabeli, co oznacza, że pole oznaczone jako klucz podstawowy musi mieć unikalne wartości i nie może zawierać wartości NULL. Klucz podstawowy jest fundamentalnym elementem w relacyjnych bazach danych, ponieważ umożliwia tworzenie relacji między tabelami oraz zapewnia integralność danych. Na przykład, jeśli mamy tabelę 'Użytkownicy' z kolumną 'ID', która jest kluczem podstawowym, to każda wartość w tej kolumnie będzie unikalna, co pozwala na jednoznaczne identyfikowanie użytkowników. Zgodnie z normami SQL, klucz podstawowy może składać się z jednej lub wielu kolumn, a w przypadku złożonego klucza podstawowego, wszystkie kolumny muszą spełniać warunki unikalności oraz nie mogą mieć wartości NULL. W praktyce, użycie klucza podstawowego jest kluczowe dla organizacji danych i optymalizacji zapytań, ponieważ bazy danych mogą tworzyć indeksy na tych polach, co przyspiesza operacje wyszukiwania i sortowania.