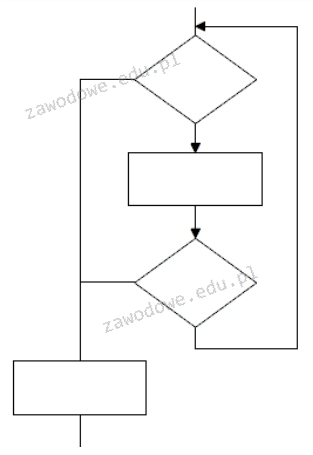
Pytanie 1
W trakcie weryfikacji stron internetowych nie analizuje się
A. funkcjonowania linków
B. zgodności z różnymi przeglądarkami
C. błędów składniowych w kodzie
D. źródeł pochodzenia narzędzi edytorskich
Walidacja stron internetowych jest procesem, który ma na celu zapewnienie, że strona internetowa jest poprawnie skonstruowana i zgodna z ustalonymi standardami, co z kolei wpływa na jej funkcjonalność oraz dostępność. W tym kontekście analiza błędów składni kodu jest kluczowa, ponieważ nieprawidłowa składnia może prowadzić do błędów renderingowych w przeglądarkach, co z kolei negatywnie wpływa na doświadczenia użytkowników. Podobnie, sprawdzanie działania linków jest istotne, ponieważ nieaktywe lub uszkodzone linki mogą prowadzić do frustracji użytkowników oraz wyniszczającego wpływu na SEO. Dodatkowo, zgodność z przeglądarkami jest fundamentalnym aspektem walidacji, gdyż różne przeglądarki mogą interpretować kod HTML i CSS w odmienny sposób. Zaniedbanie tych aspektów może skutkować problemami z wyświetlaniem strony czy jej funkcjonalnością. Typowym błędem myślowym, który prowadzi do niewłaściwych wniosków, jest przekonanie, że źródło narzędzi edytorskich - czy to komercyjne, czy open-source - ma bezpośredni wpływ na jakość kodu. Prawda jest taka, że to programista jest odpowiedzialny za jakość tworzonych rozwiązań, a nie samo narzędzie. Również, często myli się korzyści płynące z używania profesjonalnego edytora kodu z jego wpływem na proces walidacji, co prowadzi do niewłaściwego podejścia do oceny jakości strony internetowej.