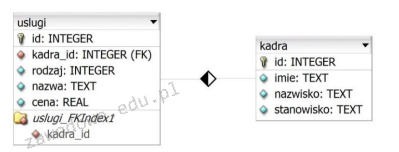
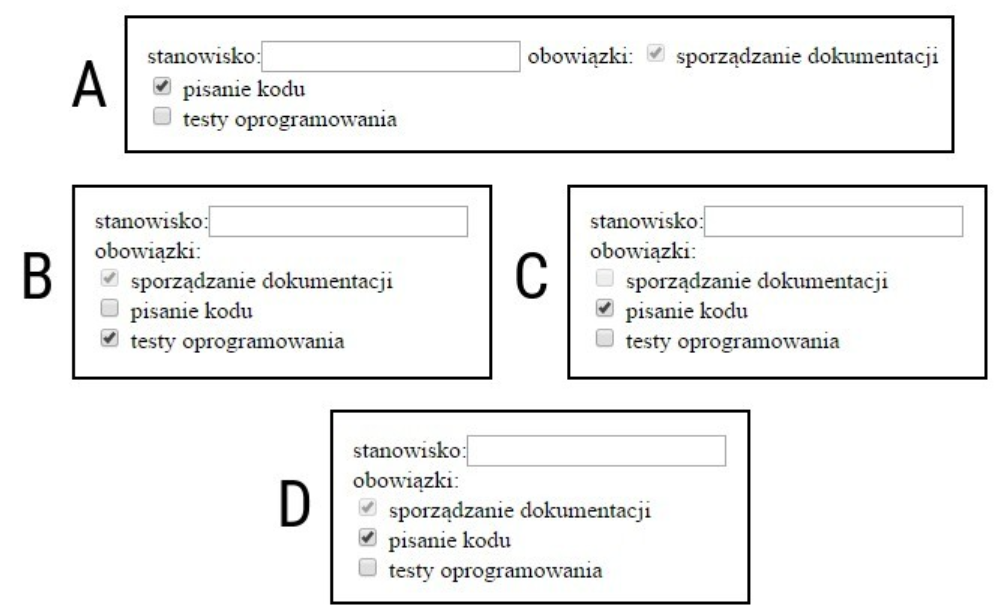
Pytanie 1
Na podstawie filmu wskaż, która cecha dodana do stylu CSS zamieni miejscami bloki aside i nav, pozostawiając w środku blok section?
A. nav { float: right; } section { float: right; }
B. nav { float: left; } aside { float: left; }
C. aside {float: left; }
D. nav { float: right; }
W tym zadaniu kluczowe jest zrozumienie, jak naprawdę działa float, a nie tylko samo skojarzenie, że „left to lewo, right to prawo”. Wiele osób myśli, że wystarczy ustawić jeden element na lewo, drugi na prawo i wszystko magicznie się poukłada. W praktyce przeglądarka trzyma się bardzo konkretnych reguł: najpierw liczy kolejność elementów w HTML, potem dopiero stosuje float i układa je możliwie jak najwyżej i jak najbliżej odpowiedniej krawędzi. Jeśli nada się float tylko dla aside albo tylko dla nav, to zmienia się ich pozycja, ale układ trzech bloków nie spełni warunku z zadania: aside i nav nie zamienią się miejscami z pozostawieniem section w środku. Przykładowo, samo float: left na aside niczego nie „zamieni”, bo element i tak pojawia się jako pierwszy w kodzie, więc będzie u góry, tylko że „przyklejony” do lewej. Z kolei ustawienie nav na prawą stronę bez odpowiedniego floatowania section prowadzi do sytuacji, gdzie section nadal zachowuje się jak normalny blok, zwykle ląduje pod elementami pływającymi albo obok nich w sposób mało przewidywalny dla początkującego. Częsty błąd myślowy polega też na tym, że ktoś próbuje wszystkim elementom dać float: left, licząc na to, że przeglądarka „ułoży je po swojemu”. Wtedy jednak wszystkie te bloki ustawiają się w jednym kierunku, w kolejności z HTML, więc nie ma mowy o świadomym „zamienianiu miejsc”. Brak zrozumienia, że float wyjmuje element z normalnego przepływu i wpływa na to, jak kolejne elementy zawijają się wokół niego, prowadzi właśnie do takich błędnych odpowiedzi. Z mojego doświadczenia lepiej jest najpierw narysować sobie prosty schemat: w jakiej kolejności idą znaczniki i które z nich mają pływać w prawo, a które zostać w naturalnym układzie. Dopiero wtedy dobiera się konkretne deklaracje CSS. Takie myślenie przydaje się nie tylko przy float, ale też przy nauce flexboxa czy grida, gdzie kolejność w DOM i własności układu też grają ogromną rolę.