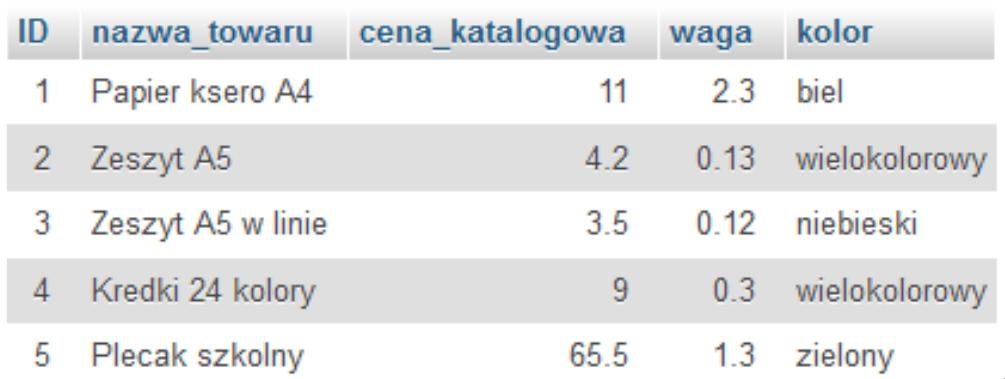
Pytanie 1
W dokumencie XHTML znajduje się fragment kodu, który posiada błąd w walidacji. Na czym ten błąd polega? ```
tekst
pierwsza linia
Druga linia
A. Znaczniki powinny być zapisywane dużymi literami
B. Nie ma nagłówka szóstego stopnia
C. Znacznik <b> nie może być umieszczany wewnątrz znacznika <p>
D. Znacznik <br> musi być zamknięty
W odpowiedzi wskazano, że znacznik <br> powinien być zamknięty, co jest zgodne z zasadami XHTML. W przeciwieństwie do HTML, w XHTML każdy znacznik musi być poprawnie zamknięty, aby kod był zgodny ze standardami. W przypadku znacznika <br>, który służy do wstawienia łamania linii, powinien być zapisany jako <br /> w XHTML. Taki sposób zapisu zapewnia, że dokument jest poprawnie zinterpretowany przez przeglądarki i inne narzędzia przetwarzające. Warto również zaznaczyć, że poprawne zamykanie znaczników jest kluczowe dla utrzymania struktury dokumentu i jego walidacji, co wpływa na dostępność i SEO. Praktyczne przykłady obejmują tworzenie dokumentów XHTML, w których konsekwentnie stosuje się poprawną składnię, co ułatwia ich przyszłą edycję i utrzymanie. Zastosowanie poprawnych standardów, takich jak XHTML, jest również dobre dla interoperacyjności między różnymi platformami i aplikacjami.