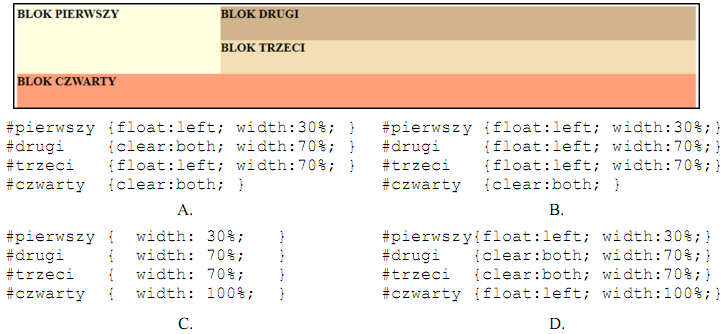
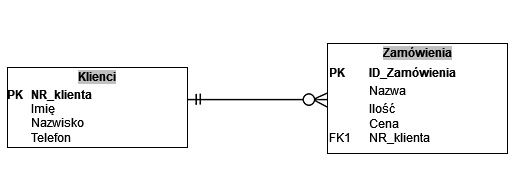
Pytanie 1
W języku PHP zapisano fragment kodu. Plik cookie stworzony tym poleceniem
| setcookie("osoba", "Anna Kowalska", time() + (3600 * 24)); |
A. będzie przechowywany na serwerze przez jeden dzień.
B. zostanie usunięty po jednym dniu od jego utworzenia.
C. zostanie usunięty po jednej godzinie od jego utworzenia.
D. będzie przechowywany na serwerze przez jedną godzinę.
Widzę, że pomyślałeś, że plik cookie będzie trzymany na serwerze. To nie tak, bo wszystkie pliki cookie są przechowywane na komputerze użytkownika, a nie na serwerze. Serwer tylko korzysta z tych cookies, żeby wiedzieć, kto jest użytkownikiem i jak zarządzać sesjami. Kolejna sprawa – niektórzy myślą, że cookie wygasa po godzinie. Ale to nieprawda, bo w PHP argument wygaszenia to 3600 * 24, czyli 86400 sekund, co daje jeden dzień, a nie tylko godzinę. Te nieporozumienia mogą wynikać z braku zrozumienia funkcji setcookie() i tego, jak działają pliki cookie w webowych aplikacjach. Dobrze jest to wiedzieć, by tworzyć lepsze i bezpieczniejsze aplikacje.