Pytanie 1
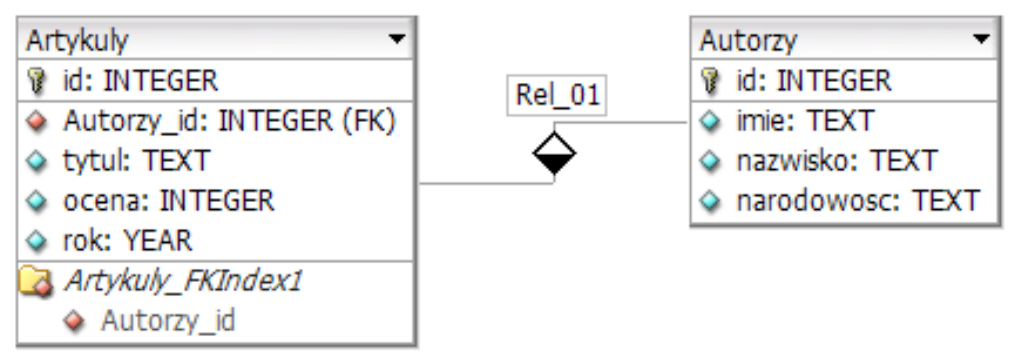
Integralność encji w systemie baz danych będzie zapewniona, jeśli między innymi
A. klucz główny zawsze będzie liczbą całkowitą
B. dla każdej tabeli zostanie ustanowiony klucz główny
C. każdy klucz główny będzie miał odpowiadający mu klucz obcy w innej tabeli
D. każda kolumna otrzyma zdefiniowany typ danych
Brak odpowiedzi na to pytanie.
Wyjaśnienie poprawnej odpowiedzi:
Odpowiedź, że dla każdej tabeli zostanie utworzony klucz główny, jest prawidłowa, ponieważ klucz główny odgrywa kluczową rolę w zapewnieniu integralności encji w bazach danych. Klucz główny to unikalny identyfikator dla każdego rekordu w tabeli, co oznacza, że nie może zawierać wartości NULL i musi być unikalny w obrębie danej tabeli. Przykładowo, w tabeli 'Klienci', kolumna 'ID_klienta' może być kluczem głównym, który jednoznacznie identyfikuje każdego klienta. Umożliwia to nie tylko prawidłową organizację danych, ale także przyspiesza operacje wyszukiwania i modyfikacji. Dodatkowo, zgodnie z normami ACID, klucz główny jest niezbędny do zapewnienia spójności i integralności danych. Dobrze zdefiniowane klucze główne są również podstawą do tworzenia kluczy obcych, co pozwala na tworzenie relacji między tabelami i wspiera strukturyzację danych w relacyjnych bazach danych.
Odpowiedź, że dla każdej tabeli zostanie utworzony klucz główny, jest prawidłowa, ponieważ klucz główny odgrywa kluczową rolę w zapewnieniu integralności encji w bazach danych. Klucz główny to unikalny identyfikator dla każdego rekordu w tabeli, co oznacza, że nie może zawierać wartości NULL i musi być unikalny w obrębie danej tabeli. Przykładowo, w tabeli 'Klienci', kolumna 'ID_klienta' może być kluczem głównym, który jednoznacznie identyfikuje każdego klienta. Umożliwia to nie tylko prawidłową organizację danych, ale także przyspiesza operacje wyszukiwania i modyfikacji. Dodatkowo, zgodnie z normami ACID, klucz główny jest niezbędny do zapewnienia spójności i integralności danych. Dobrze zdefiniowane klucze główne są również podstawą do tworzenia kluczy obcych, co pozwala na tworzenie relacji między tabelami i wspiera strukturyzację danych w relacyjnych bazach danych.