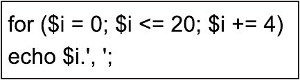Pytanie 1
Wskaż funkcję w JavaScript, która pozwoli obliczyć połowę kwadratu liczby podanej jako argument.
A. function wynik(a) { return 2*a/a; }
B. function wynik(a) { return a/2+a/2; }
C. function wynik(a) { return a*2/2; }
D. function wynik(a) { return a*a/2; }
Funkcja function wynik(a) { return a*a/2; } jest całkiem w porządku. Działa, bo fajnie oblicza połowę kwadratu liczby, którą podajesz jako argument. W praktyce, 'a*a' to nic innego jak kwadrat liczby 'a', a potem dzielimy to przez 2, co nam daje wartość połowy tego kwadratu. To, co zrobiłeś, jest zgodne z zasadami matematyki i jak na programowanie w JavaScript to też się sprawdza. Na przykład, jak podstawisz '4', to funkcja zwróci 8, bo (4*4)/2 = 16/2 = 8. Takie obliczenia mogą się przydać w różnych aplikacjach, np. przy obliczeniach inżynieryjnych czy analizie danych, gdzie często korzysta się z takich wzorów. Użycie zmiennych i funkcji w programowaniu ułatwia zarządzanie danymi, a do tego można łatwiej się orientować w kodzie, co jest super.