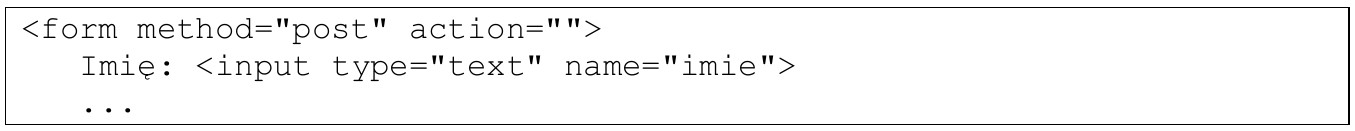Pytanie 1
Które z komend przyznaje najniższy poziom uprawnień dla użytkownika uczen w zakresie modyfikacji danych oraz struktury tabeli?
A. DRANT DROP ON szkola.przedmioty TO uczen
B. GRANT SELECT ON szkola.przedmioty TO uczen
C. GRANT INSERT, DROP ON szkola.przedmioty TO uczen
D. GRANT ALTER, SELECT ON szkola.przedmioty TO uczen
Wszystkie pozostałe polecenia przyznają użytkownikowi uczeń szerszy zakres uprawnień, co prowadzi do większego ryzyka nieautoryzowanej modyfikacji danych. Polecenie DRANT DROP ON szkola.przedmioty TO uczen jest nieprawidłowe, ponieważ DRANT nie jest poprawnym poleceniem SQL, co czyni jego interpretację niemożliwą. W kontekście administracji bazami danych, DROP oznacza usunięcie całej tabeli, co w przypadku użytkownika uczeń może prowadzić do katastrofalnych skutków, gdyż może on przypadkowo lub celowo usunąć istotne dane. Kolejne polecenie GRANT INSERT, DROP ON szkola.przedmioty TO uczen przyznaje prawo do wstawiania nowych danych oraz usuwania tabeli. Takie uprawnienia są zdecydowanie nieodpowiednie dla użytkownika uczeń. Umożliwiają one nie tylko dodawanie nieautoryzowanych rekordów, ale także ich usuwanie, co narusza zasady bezpieczeństwa i integralności danych. Podobnie, GRANT ALTER, SELECT ON szkola.przedmioty TO uczen przyznaje prawo do modyfikacji struktury tabeli, co oznacza, że uczeń mógłby zmieniać kolumny, dodawać nowe oraz wprowadzać zmiany, które mogą wpływać na funkcjonowanie całej bazy danych. Prawo do ALTER jest jednym z najszerszych uprawnień w SQL i nie powinno być przyznawane użytkownikom, którzy nie są administratorami, aby zapewnić pełną kontrolę nad bazą danych.