Odtwarzaj przebieg egzaminu krok po kroku i ucz się na własnych błędach. Widzisz dokładnie, w jakiej kolejności rozwiązywałeś pytania, ile czasu spędziłeś nad każdym z nich i kiedy zmieniałeś odpowiedzi.
Co znajdziesz na stronie przebiegu:
Suwak czasu
Przesuwaj i przeglądaj pytania w kolejności, w jakiej je rozwiązywałeś
Tryb nauki
Włącz, aby zobaczyć poprawne odpowiedzi i wyjaśnienia do pytań
Analiza czasu
Sprawdź, ile czasu spędziłeś nad każdym pytaniem i gdzie traciłeś czas
Monitoring focusu
Widzisz momenty, gdy opuściłeś zakładkę - tak jak widzi to nauczyciel
Która z reguł dotyczących sekcji w języku HTML jest poprawna?
A. W sekcji <head> umieszcza się część <body>
B. W sekcji <head> mogą znajdować się znaczniki <meta>, <title>, <link>
C. W sekcji <head> można zdefiniować szablon strony przy użyciu znaczników <div>
D. W sekcji <head> nie można umieszczać kodu CSS, jedynie odwołanie do pliku CSS
Wybór tej odpowiedzi jest słuszny, ponieważ w części <head> dokumentu HTML mogą występować różne znaczniki, które są kluczowe dla poprawnej struktury i funkcjonalności strony. Znaczniki <meta> służą do dostarczania danych o stronie, takich jak opis, słowa kluczowe czy informacje o autorze, co jest istotne dla SEO (optymalizacji pod kątem wyszukiwarek). Znacznik <title> definiuje tytuł strony, który jest wyświetlany w zakładkach przeglądarki oraz w wynikach wyszukiwania, co ma wpływ na wrażenia użytkowników oraz ich decyzje. Z kolei znacznik <link> jest używany do odwoływania się do zewnętrznych arkuszy stylów CSS, co pozwala na oddzielenie struktury HTML od stylizacji. Dobre praktyki wskazują, że umieszczanie CSS w <head> zamiast w <body> poprawia czas ładowania strony oraz zapewnia, że style są stosowane jeszcze przed renderowaniem zawartości, co wpływa na lepszą użyteczność i wygląd strony. Dobrze zorganizowana sekcja <head> może przyczynić się do lepszego pozycjonowania w wyszukiwarkach oraz poprawy doświadczeń użytkowników.
Pytanie 2
Język JavaScrypt umożliwia obsługę
A. funkcji wirtualnych
B. obiektów DOM
C. klas abstrakcyjnych
D. wysyłania ciastek z identycznymi informacjami do wielu klientów strony
Obsługa funkcji wirtualnych nie jest częścią języka JavaScript, ponieważ ten język nie obsługuje typów i mechanizmów programowania obiektowego w sposób, w jaki robią to inne języki, takie jak C++ czy Java. JavaScript nie posiada koncepcji 'wirtualnych funkcji', które są charakterystyczne dla języków, które implementują mechanizmy dziedziczenia oparte na klasach. W JavaScript, programowanie obiektowe opiera się na prototypach, co oznacza, że obiekty mogą dziedziczyć właściwości i metody bez użycia wirtualnych funkcji, co czyni to pojęcie nieadekwatnym w kontekście tego języka. Ponadto, klasa abstrakcyjna jest także pojęciem, które jest źle zrozumiane w kontekście JavaScript. W rzeczywistości, JavaScript nie wspiera klas abstrakcyjnych w tradycyjnym sensie znanym z języków statycznie typowanych. Wprowadzenie klas w ECMAScript 6 dodało nową składnię, ale nie zmieniło fundamentalnej natury języka. JavaScript nie wymusza implementacji metod w klasach pochodnych, co jest kluczowym aspektem klas abstrakcyjnych. Wreszcie, kwestia wysyłania ciastek z tą samą informacją do wielu klientów stron internetowych odnosi się bardziej do mechanizmów serwerowych i zarządzania sesjami niż do samego języka JavaScript. JavaScript działa głównie po stronie klienta, a ciasteczka są zarządzane przez przeglądarki internetowe, gdzie mogą być ustalane przez skrypty, ale samo wysyłanie ciasteczek do klientów nie jest bezpośrednio związane z jego funkcjonalnością. Te aspekty techniczne ukazują, dlaczego podane odpowiedzi nie są poprawne w kontekście pytania o obsługę JavaScript.
Pytanie 3
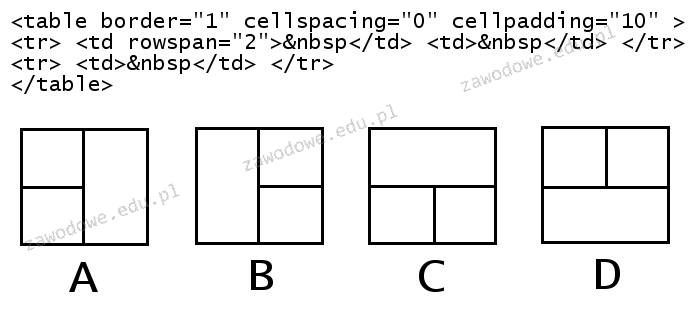
Funkcja colspan umożliwia łączenie komórek tabeli w układzie poziomym, natomiast rowspan w układzie pionowym. Która z poniższych tabel odpowiada fragmentowi kodu w języku HTML?
A. Odpowiedź A
B. Odpowiedź C
C. Odpowiedź D
D. Odpowiedź B
Rozumienie działania atrybutów rowspan i colspan jest kluczowe dla prawidłowego tworzenia struktur tabelarycznych w HTML. Błędne odpowiedzi wynikają często z nieporozumienia dotyczącego sposobu, w jaki te atrybuty kształtują układ tabeli. Rowspan, jak sama nazwa wskazuje, łączy komórki w pionie, czyli wzdłuż kolumny, co może być źródłem zamieszania dla osób przyzwyczajonych do myślenia bardziej w kategoriach kolumn niż wierszy. Przy błędnym przypisaniu rowspan można oczekiwać komórek rozciągających się w poziomie, co jest funkcją colspan. Typowym błędem jest także założenie, że rowspan i colspan są zamienne, podczas gdy w rzeczywistości służą do różnych celów i mają różne zastosowania. Ważne jest, aby rozumieć, że rowspan zwiększa wysokość komórki poprzez zajęcie miejsca w kolejnych wierszach, co jest istotne przy projektowaniu układów tabel, które muszą być zarówno funkcjonalne, jak i estetycznie poprawne. Prawidłowe użycie rowspan i colspan zgodnie z zasadami semantyki HTML zwiększa dostępność i użyteczność stron, co jest zgodne z najlepszymi praktykami w branży.
Pytanie 4
Jak utworzyć klucz obcy na wielu kolumnach podczas definiowania tabeli?
A. CONSTRAINT fk_osoba_uczen FOREIGN KEY(nazwisko, imie) REFERENCES osoby (nazwisko, imie)
B. CONSTRAINT (nazwisko, imie) FOREIGN REFERENCES KEY osoby (nazwisko, imie)
C. CONSTRAINT fk_osoba_uczen FOREIGN KEY ON(nazwisko, imie) REFERENCES osoby (nazwisko, imie)
D. CONSTRAINT (nazwisko, imie) FOREIGN KEY REFERENCES osoby (nazwisko, imie)
Aby utworzyć klucz obcy na wielu kolumnach w relacyjnej bazie danych, używamy konstrukcji SQL, która specyfikuje klauzulę CONSTRAINT, a następnie definiuje składniki klucza obcego. W przypadku podanej poprawnej odpowiedzi, mamy do czynienia z konstrukcją, która jest zgodna z standardem SQL. Klucz obcy łączy dwie tabele, zapewniając integralność referencyjną, co oznacza, że wartości w kolumnach klucza obcego muszą odpowiadać wartościom w kolumnach klucza podstawowego w innej tabeli. W tym przypadku klucz obcy odnosi się do kolumn 'nazwisko' i 'imie' w tabeli 'osoby'. Dodatkowo, poprawna składnia 'FOREIGN KEY(nazwisko, imie)' wskazuje, które kolumny w bieżącej tabeli są kluczem obcym, a 'REFERENCES osoby (nazwisko, imie)' wskazuje, że te kolumny odnoszą się do kolumn w tabeli 'osoby'. Przykładowo, jeśli mamy tabelę 'uczniowie', która przechowuje dane uczniów, to klucz obcy może pomóc w powiązaniu ich z tabelą 'osoby', co jest niezwykle istotne dla zachowania spójności danych oraz unikania anomalii podczas operacji CRUD (Create, Read, Update, Delete).
Pytanie 5
Jak można zmodyfikować nałożone na siebie fragmenty obrazu, nie zmieniając innych elementów?
A. Przycinanie
B. Kanał przezroczystości
C. Warstwy
D. Wykres histogramu
Warstwy są kluczowym elementem w edycji grafiki komputerowej, umożliwiając precyzyjne zarządzanie różnymi elementami obrazu. Dzięki zastosowaniu warstw, użytkownik może na przykład oddzielić tło od obiektów na pierwszym planie, co pozwala na edytowanie jednego z tych elementów bez wpływu na resztę kompozycji. Zastosowanie warstw jest szczególnie przydatne w programach graficznych, takich jak Adobe Photoshop, GIMP czy CorelDRAW, gdzie umożliwia łatwą manipulację oraz efektywną organizację projektu. Dzięki warstwom można również stosować różne efekty i style, takie jak cienie, przezroczystości czy gradienty, co pozwala na stworzenie bardziej złożonych i interesujących grafik. Warto również zauważyć, że korzystanie z warstw jest zgodne z najlepszymi praktykami w branży, jako że sprzyja to lepszej organizacji pracy oraz ułatwia wprowadzanie zmian w projekcie. Uczy to również umiejętności przydatnych w pracy zespołowej, gdzie różne osoby mogą pracować nad różnymi warstwami równocześnie, co zwiększa efektywność i kreatywność procesu twórczego.
Pytanie 6
Określ rezultat wykonania skryptu stworzonego w języku PHP
A. C
B. D
C. A
D. B
Odpowiedź A jest prawidłowa, ponieważ funkcja asort() w PHP sortuje tablicę asocjacyjną według wartości w porządku rosnącym, ale zachowuje oryginalne klucze. W tym przypadku mamy tablicę z wartościami tekstowymi. Funkcja asort() posortuje te wartości alfabetycznie, co oznacza, że najpierw pojawi się 'Perl', następnie 'PHP', 'Pike' i na końcu 'Python'. Klucze zostaną przypisane do odpowiednich wartości, co jest widoczne w odpowiedzi A. Użycie asort() jest bardzo przydatne, gdy chcemy zachować związki między kluczami i wartościami w tablicach asocjacyjnych, jednocześnie sortując je według wartości. Dobrą praktyką jest używanie tej funkcji w sytuacjach, gdzie klucze mają znaczenie, takie jak przetwarzanie danych konfiguracyjnych lub wyników ankiet. Dodatkowo, rozumienie różnic między funkcjami sortującymi w PHP jak sort(), asort(), ksort(), usort(), uasort() i uksort() jest kluczowe w efektywnym manipulowaniu danymi w skryptach PHP, pozwalając na precyzyjną kontrolę nad strukturami danych i ich porządkowaniem.
Pytanie 7
W systemie MySQL trzeba użyć polecenia REVOKE, aby użytkownikowi anna cofnąć możliwość wprowadzania zmian jedynie w definicji struktury bazy danych. Odpowiednia komenda do odebrania tych uprawnień ma postać
A. REVOKE CREATE INSERT DELETE ON tabela1 FROM 'anna'@'localhost'
B. REVOKE CREATE ALTER DROP ON tabela1 FROM 'anna'@'localhost'
C. REVOKE CREATE UPDATE DROP ON tabela1 FROM 'anna'@'localhost'
D. REVOKE ALL ON tabela1 FROM 'anna'@'locaihost'
W analizie odpowiedzi, które są niepoprawne, kluczowe jest zrozumienie, jakie uprawnienia są odbierane i dlaczego to ma znaczenie. Odpowiedzi takie jak 'REVOKE ALL ON tabela1 FROM 'anna'@'localhost'' są niewłaściwe, ponieważ polecenie REVOKE ALL odbiera wszystkie prawa użytkownikowi, co może być zbyt drastycznym krokiem. W kontekście zarządzania uprawnieniami, ważne jest, aby podejść do tego z miarą i precyzją, a nie stosować ogólne odbieranie wszystkich praw. Ponadto, odpowiedzi, które obejmują niewłaściwe kombinacje uprawnień, takie jak 'REVOKE CREATE UPDATE DROP ON tabela1 FROM 'anna'@'localhost'', są również błędne. Odbieranie prawa UPDATE nie jest zgodne z celem pytania, które dotyczy jedynie strukturalnych zmian, a nie wprowadzania danych. Właściwe podejście do konfiguracji uprawnień powinno koncentrować się na ograniczaniu dostępu użytkowników tylko tam, gdzie jest to absolutnie konieczne, a nie na eliminacji ich zdolności do pracy z danymi w ogóle. Użytkownicy często popełniają błąd myślowy, myśląc, że odebranie zbyt wielu uprawnień jest rozwiązaniem problemu bezpieczeństwa, podczas gdy w rzeczywistości może to prowadzić do zablokowania niezbędnych operacji, co zagraża efektywności pracy organizacji.
Pytanie 8
Jakie polecenie pozwala na zwiększenie wartości o jeden w polu RokStudiów w tabeli Studenci dla tych studentów, którzy są na roku 1÷4?
A. UPDATE Studenci, RokStudiow+1 WHERE RokStudiow < 5
B. UPDATE Studenci SET RokStudiow WHERE RokStudiow < 5
C. UPDATE Studenci SET RokStudiow = RokStudiow+1 WHERE RokStudiow < 5
D. UPDATE RokStudiow SET RokStudiow++ WHERE RokStudiow < 5
Odpowiedź 'UPDATE Studenci SET RokStudiow = RokStudiow+1 WHERE RokStudiow < 5;' jest poprawna, ponieważ stosuje właściwą składnię SQL do aktualizacji wartości w kolumnie RokStudiow w tabeli Studenci. Użycie słowa kluczowego 'SET' pozwala na przypisanie nowej wartości do atrybutu, a 'WHERE RokStudiow < 5' zapewnia, że tylko studenci z rokiem studiów od 1 do 4 zostaną zaktualizowani. Przykładowo, jeśli mamy studentów na roku 1, 2, 3 oraz 4, po wykonaniu tego polecenia ich rok studiów wzrośnie o 1, co jest zgodne z praktyką zwiększania roku studiów po zakończeniu danego etapu edukacji. W kontekście dobrych praktyk w programowaniu, warto również dbać o to, aby zapytania były jasne i zrozumiałe, a operacje aktualizacji mogły być łatwo śledzone i analizowane w przyszłości. Odpowiednie użycie komentarzy oraz testowanie zapytań w warunkach niskiego obciążenia bazy danych przed ich wdrożeniem w środowisku produkcyjnym to kluczowe aspekty zapewnienia bezpieczeństwa i integralności danych.
Pytanie 9
W pokazanym fragmencie zapytania w języku SQL, polecenie SELECT ma na celu uzyskanie wyników z komendy SELECT COUNT(wartosc) FROM....?
A. średnią wartości w kolumnie wartosc
B. sumę wartości w kolumnie wartosc
C. liczbę rekordów
D. średnią wartości w tabeli
W kontekście zapytania SQL, komenda SELECT COUNT(wartosc) ma na celu zwrócenie liczby wierszy w danej tabeli, które spełniają określone kryteria. Funkcja COUNT jest jedną z agregujących funkcji zapytań SQL, która zlicza liczbę niepustych wartości w kolumnie. Jeżeli argumentem funkcji jest konkretna kolumna, to zostaną zliczone tylko te wiersze, w których ta kolumna zawiera wartości, natomiast jeżeli użyjemy COUNT(*) bez podawania kolumny, zliczymy wszystkie wiersze tabeli, niezależnie od tego, czy kolumny zawierają wartości. Przykład praktyczny: jeśli mamy tabelę 'Zamówienia' i chcemy zliczyć liczbę dokonanych zamówień, można użyć zapytania SELECT COUNT(*) FROM Zamówienia; co zwróci całkowitą liczbę zamówień w tabeli. Istotne jest, aby zrozumieć, że COUNT zwraca liczbę wierszy, a nie sumę, średnią lub inne statystyki. W standardzie SQL nie ma specyfikacji, która by zmieniała tę funkcjonalność, co czyni ją uniwersalną w różnych bazach danych, takich jak MySQL, PostgreSQL, czy SQL Server.
Pytanie 10
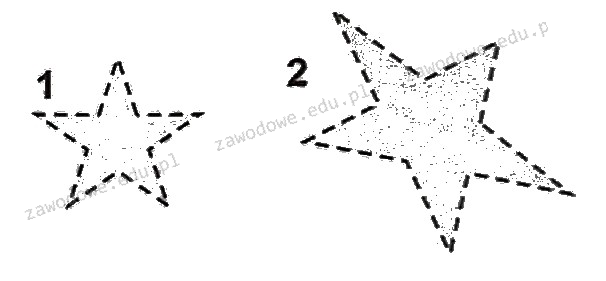
Najłatwiejszym sposobem na zmianę obiektu z numerem 1 na obiekt z numerem 2 jest
A. narysowanie obiektu docelowego
B. animacja obiektu
C. zmiana warstwy obiektu
D. geometriczne przekształcenie obiektu
Geometryczne transformowanie obiektu to proces, który pozwala na zmiany w wielkości, kształcie, pozycji lub orientacji obiektu bez modyfikacji jego struktury. W przypadku zamiany obiektu oznaczonego cyfrą 1 na obiekt oznaczony cyfrą 2, transformacja geometryczna, jak skalowanie, jest najprostszą metodą. Skalowanie pozwala na proporcjonalne powiększenie obiektu, co jest niezbędne, gdy chcemy zwiększyć jego rozmiar bez zniekształceń. W praktyce, narzędzia do obróbki grafiki czy modelowania 3D, takie jak Adobe Illustrator czy AutoCAD, oferują funkcje do precyzyjnego skalowania. Kluczowe jest zachowanie proporcji, co można osiągnąć poprzez skalowanie względem określonego punktu odniesienia. Transformacje geometryczne są fundamentalne w wielu dziedzinach, takich jak projektowanie graficzne, inżynieria czy animacja komputerowa, i są zgodne z najlepszymi praktykami, które promują efektywność i precyzję w pracy z obiektami wizualnymi.
Pytanie 11
W języku PHP przeprowadzono operację przedstawioną w ramce. Jak można postąpić, aby wyświetlić wszystkie wyniki tego zapytania?
$tab = mysqli_query($db, "SELECT imie FROM Osoby WHERE wiek < 18");
A. zaindeksować zmienną tab, tab[0] to pierwsze imię
B. zastosować pętlę z poleceniem mysqli_fetch_row
C. użyć polecenia mysql_fetch
D. pokazać zmienną $db
Prawidłowa odpowiedź dotyczy zastosowania pętli z poleceniem mysqli_fetch_row. W języku PHP przy pracy z bazą danych MySQL wykorzystujemy bibliotekę mysqli, która oferuje funkcje pozwalające na manipulację danymi. Funkcja mysqli_query wykonuje zapytanie SQL na połączeniu z bazą danych, zwracając wynik w postaci obiektu typu mysqli_result. Aby pobrać wszystkie wiersze wyników, konieczne jest zastosowanie pętli, która iteruje przez każdy wiersz zwracany przez zapytanie. Funkcja mysqli_fetch_row jest używana do pobrania kolejnego wiersza z wyniku jako tablicy numerycznej. Przykładowy kod mógłby wyglądać następująco while ($row = mysqli_fetch_row($tab)) { echo $row[0]; } co pozwala na wyświetlenie imion wszystkich osób poniżej 18 roku życia. Praktyczne podejście polega na iteracyjnej obsłudze wyników zapytań, co jest zgodne z branżowymi standardami. Takie rozwiązanie umożliwia dynamiczne przetwarzanie danych w czasie rzeczywistym zwiększając elastyczność aplikacji. Dodatkowo warto pamiętać o odpowiednim zarządzaniu zasobami, takim jak zamknięcie połączenia z bazą danych po zakończeniu operacji. To podejście podkreśla znaczenie efektywnego zarządzania danymi w aplikacjach webowych.
Pytanie 12
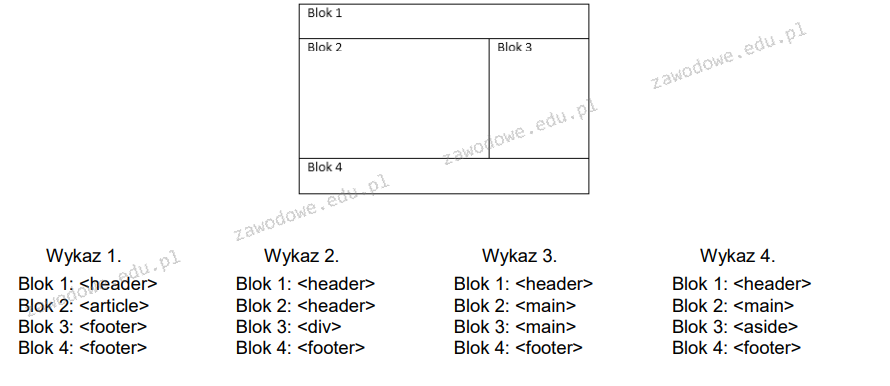
Który zbiór znaczników, określających projekt strony internetowej w sposób semantyczny, jest zgodny z normą HTML 5?
A. Zbiór 2
B. Zbiór 3
C. Zbiór 4
D. Zbiór 1
Zrozumienie semantyki HTML jest kluczowe dla tworzenia zoptymalizowanych stron internetowych, a wybór odpowiednich znaczników ma duży wpływ na strukturę i dostępność dokumentu. W niepoprawnych odpowiedziach brak jest semantycznej spójności z założeniami HTML5. Wykaz 1 używa <article> w Bloku 2, co oznaczałoby samodzielną jednostkę, np. wpis na blogu lub artykuł prasowy, co nie jest odpowiednie w kontekście głównej treści strony. Wykaz 2 używa <div>, co jest niezalecane, gdyż divy są ogólnymi kontenerami, a HTML5 promuje użycie bardziej szczegółowych znaczników semantycznych. Wykaz 3 zastosował <main> dwukrotnie, co jest błędem, ponieważ <main> powinien być użyty tylko raz na stronie, jako główny element zawartości. Pominięcie znaczników takich jak <aside> lub <header> w odpowiednich miejscach zubaża strukturę dokumentu, co wpływa negatywnie na SEO i dostępność. Zasady semantyczności w HTML5 mają na celu ułatwienie interpretacji kodu zarówno przez przeglądarki, jak i przez urządzenia wspomagające, co jest kluczowe w nowoczesnym projektowaniu stron internetowych. Właściwe oznaczenie elementów strony pozwala na lepszą organizację treści i ułatwia nawigację, co jest ważne dla użytkowników i wyszukiwarek internetowych.
Pytanie 13
W kodzie HTML atrybut alt w tagu img służy do określenia
A. atrybutów obrazu, takich jak rozmiar, ramka, wyrównanie
B. ścieżki oraz nazwy pliku źródłowego
C. opisu, który pojawi się pod obrazem
D. tekstu, który będzie prezentowany, gdy obraz nie może być załadowany
Atrybut alt w znaczniku img w HTML to naprawdę ważny element, jeśli chodzi o dostępność stron www. Jego głównym zadaniem jest pomóc osobom z problemami ze wzrokiem zrozumieć, co widnieje na obrazku. Jeśli nie da się wyświetlić grafiki – na przykład przez zły internet czy błąd w ścieżce do pliku – tekst w atrybucie alt pokazuje się jako alternatywa. Na przykład <img src='example.jpg' alt='Zachód słońca nad morzem'>, co by ułatwiło osobom korzystającym z czytników ekranu zrozumienie treści. Warto też pamiętać, że ten atrybut ma znaczenie dla SEO, bo wyszukiwarki mogą go wykorzystać do lepszego zrozumienia zawartości strony, co wpływa na jej indeksowanie. Ogólnie rzecz biorąc, używanie odpowiednich atrybutów alt to dobra praktyka w budowaniu stron www.
Pytanie 14
Jakim sposobem w języku PHP można zapisać komentarz zajmujący kilka linii?
A. /* */
B. //
C. #
D. <!-- -->
W języku PHP, sposób komentowania bloku komentarza w kilku liniach to użycie znaków /* i */. Taki sposób pozwala na umieszczenie dowolnej ilości tekstu w obrębie tych znaków, co jest niezwykle przydatne, gdy chcemy opisać bardziej złożoną funkcję lub fragment kodu. Na przykład, w czasie tworzenia dokumentacji kodu, często stosujemy bloki komentarzy do szczegółowego opisania działania funkcji, parametrów oraz zwracanych wartości. Dzięki temu każdy programista, który będzie pracował z naszym kodem w przyszłości, może szybko zrozumieć jego przeznaczenie. Dobrą praktyką jest również umieszczanie daty aktualizacji oraz informacji o autorze w takich blokach, co ułatwia zarządzanie projektem. Stosowanie bloków komentarzy jest zgodne z konwencjami programistycznymi, co zwiększa czytelność kodu i jego późniejszą konserwację.
Pytanie 15
Które polecenie SQL zaktualizuje w tabeli tab wartość Ania na Zosia w kolumnie kol?
A. ALTER TABLE tab CHANGE kol='Zosia' kol='Ania';
B. UPDATE tab SET kol='Ania' WHERE kol='Zosia';
C. UPDATE tab SET kol='Zosia' WHERE kol='Ania';
D. ALTER TABLE tab CHANGE kol='Ania' kol='Zosia';
W tym przypadku, żeby zmienić 'Ania' na 'Zosia' w kolumnie 'kol' w tabeli 'tab', wykorzystujemy polecenie UPDATE. To umożliwia nam modyfikację danych, które już są w bazie. Składnia jest dosyć prosta: UPDATE nazwa_tabeli SET kolumna='nowa_wartość' WHERE warunek. Więc w tym naszym przykładzie, musimy ustalić, że w kolumnie 'kol' jest obecnie 'Ania', żeby wymienić ją na 'Zosia'. Jak to napiszesz, to będzie wyglądać tak: UPDATE tab SET kol='Zosia' WHERE kol='Ania';. Tego typu polecenia są naprawdę przydatne, zwłaszcza w systemach CRM, gdzie często aktualizujemy dane o klientach. Co ciekawe, stosując SQL, działamy zgodnie z zasadami ACID, co sprawia, że nasze dane zachowują spójność. Nie zapomnij też, że przed aktualizacją warto mieć kopię zapasową, żeby w razie czego nie stracić nic ważnego.
Pytanie 16
W PHP typ float oznacza
A. typ zmiennoprzecinkowy
B. typ łańcuchowy
C. typ logiczny
D. typ całkowity
W języku PHP typ 'float' jest używany do reprezentacji liczb zmiennoprzecinkowych, co oznacza, że może on przechowywać liczby z częścią dziesiętną. Jest to kluczowy element programowania, ponieważ pozwala na bardziej precyzyjne obliczenia, które są niezbędne w wielu zastosowaniach, takich jak obliczenia finansowe czy analizy naukowe. Dzięki użyciu typu float, programiści mogą używać skomplikowanych algorytmów, które wymagają operacji na liczbach niecałkowitych. W praktyce, kiedy potrzebujemy obliczyć ceny z podatkiem lub odsetkami, użycie float pozwala na dokładniejsze wyniki niż w przypadku typów całkowitych. Należy również pamiętać, że przy pracy z typem float warto stosować funkcje takie jak round(), aby uniknąć problemów z precyzją wyników, które mogą wynikać z ograniczeń reprezentacji liczb zmiennoprzecinkowych w pamięci komputera. Warto także zaznaczyć, że zgodnie z dokumentacją PHP, float jest zgodny z standardem IEEE 754, co zapewnia jego szeroką kompatybilność z innymi systemami oraz językami programowania.
Pytanie 17
Na podstawie filmu wskaż, która cecha dodana do stylu CSS zamieni miejscami bloki aside i nav, pozostawiając w środku blok section?
A. nav { float: right; } section { float: right; }
B. nav { float: left; } aside { float: left; }
C. nav { float: right; }
D. aside {float: left; }
W tym zadaniu kluczowe jest zrozumienie, jak naprawdę działa float, a nie tylko samo skojarzenie, że „left to lewo, right to prawo”. Wiele osób myśli, że wystarczy ustawić jeden element na lewo, drugi na prawo i wszystko magicznie się poukłada. W praktyce przeglądarka trzyma się bardzo konkretnych reguł: najpierw liczy kolejność elementów w HTML, potem dopiero stosuje float i układa je możliwie jak najwyżej i jak najbliżej odpowiedniej krawędzi. Jeśli nada się float tylko dla aside albo tylko dla nav, to zmienia się ich pozycja, ale układ trzech bloków nie spełni warunku z zadania: aside i nav nie zamienią się miejscami z pozostawieniem section w środku. Przykładowo, samo float: left na aside niczego nie „zamieni”, bo element i tak pojawia się jako pierwszy w kodzie, więc będzie u góry, tylko że „przyklejony” do lewej. Z kolei ustawienie nav na prawą stronę bez odpowiedniego floatowania section prowadzi do sytuacji, gdzie section nadal zachowuje się jak normalny blok, zwykle ląduje pod elementami pływającymi albo obok nich w sposób mało przewidywalny dla początkującego. Częsty błąd myślowy polega też na tym, że ktoś próbuje wszystkim elementom dać float: left, licząc na to, że przeglądarka „ułoży je po swojemu”. Wtedy jednak wszystkie te bloki ustawiają się w jednym kierunku, w kolejności z HTML, więc nie ma mowy o świadomym „zamienianiu miejsc”. Brak zrozumienia, że float wyjmuje element z normalnego przepływu i wpływa na to, jak kolejne elementy zawijają się wokół niego, prowadzi właśnie do takich błędnych odpowiedzi. Z mojego doświadczenia lepiej jest najpierw narysować sobie prosty schemat: w jakiej kolejności idą znaczniki i które z nich mają pływać w prawo, a które zostać w naturalnym układzie. Dopiero wtedy dobiera się konkretne deklaracje CSS. Takie myślenie przydaje się nie tylko przy float, ale też przy nauce flexboxa czy grida, gdzie kolejność w DOM i własności układu też grają ogromną rolę.
Pytanie 18
GRANT CREATE, ALTER ON sklep.* TO adam; Zakładając, że użytkownik adam nie dysponował wcześniej żadnymi uprawnieniami, to polecenie SQL przyzna mu prawa jedynie do
A. tworzenia oraz modyfikacji struktury w tabeli sklep
B. wstawiania oraz modyfikacji danych we wszystkich tabelach bazy sklep
C. tworzenia oraz modyfikacji struktury wszystkich tabel w bazie sklep
D. wstawiania oraz modyfikacji danych w tabeli sklep
Odpowiedzi, które sugerują, że użytkownik adam ma ograniczone prawa tylko do konkretnej tabeli lub tylko do wstawiania i zmiany danych, wynikają z mylnego zrozumienia mechanizmu przyznawania uprawnień w SQL. W kontekście opisanego polecenia, przyznawanie praw na poziomie tabeli (sklep.*) oznacza, że wszystkie tabele w bazie danych sklep są objęte tymi uprawnieniami. W praktyce, wstawianie oraz modyfikacja danych (DML) są różnymi operacjami od tworzenia i zmiany struktury tabel (DDL). Przyznanie uprawnień CREATE i ALTER jednoznacznie wskazuje na możliwość edytowania struktury bazy, a nie tylko na manipulację danymi. Wiele osób, które mogą mylić te dwa aspekty, może zakładać, że nadanie praw do konkretnej tabeli ogranicza się do operacji na danych, co jest mylnym podejściem. Mylne jest również ograniczanie praw do jednej tabeli, gdyż polecenie dotyczy wszystkich tabel w bazie. W związku z tym, aby poprawnie zarządzać uprawnieniami w bazie danych, należy zrozumieć różnice między uprawnieniami DDL i DML oraz ich zastosowanie w kontekście całej bazy danych, nie tylko pojedynczej tabeli.
Pytanie 19
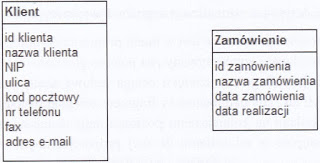
Jaką relację w projekcie bazy danych należy zdefiniować pomiędzy tabelami przedstawionymi na rysunku, zakładając, że każdy klient sklepu internetowego składa przynajmniej dwa zamówienia?
A. n:n
B. 1:n, gdzie 1 jest po stronie Zamówienia, a wiele po stronie Klienta
C. 1:n, gdzie 1 jest po stronie Klienta, a wiele po stronie Zamówienia
D. 1:1
Zrozumienie poprawnej relacji między tabelami jest kluczowe w projektowaniu bazy danych. Relacja 1:1 oznacza, że każda rekord w jednej tabeli odpowiada dokładnie jednemu rekordowi w drugiej tabeli, co w tym przypadku byłoby nieefektywne, ponieważ ogranicza możliwość dodawania wielu zamówień dla jednego klienta. W praktyce rzadko stosuje się takie relacje, chyba że dane są bardzo specyficzne i nie mogą być rozdzielone. Relacja 1:n, gdzie 1 jest po stronie Zamówienia, a wiele po stronie Klienta, jest nieprawidłowa, ponieważ implikuje, że jedno zamówienie może być przypisane wielu klientom, co jest sprzeczne z rzeczywistością e-commerce, gdzie każde zamówienie jest związane z jednym klientem. Relacja n:n sugeruje, że wiele rekordów w jednej tabeli może być powiązanych z wieloma rekordami w drugiej tabeli. Choć czasami używana, wymaga dodatkowej tabeli pośredniczącej, aby uniknąć redundancji i anomalii. W tym kontekście relacja n:n nie jest potrzebna, ponieważ prosta relacja 1:n już spełnia wymagania funkcjonalne, umożliwiając jednemu klientowi złożenie wielu zamówień bez konieczności komplikowania struktury bazy danych. Prawidłowe zrozumienie tych koncepcji pozwala na projektowanie efektywnych i wydajnych systemów bazodanowych, które są kluczowe dla sukcesu w wielu branżach, zwłaszcza w handlu elektronicznym, gdzie zarządzanie relacjami klientów i ich zamówieniami jest podstawą działalności.
Pytanie 20
Po wykonaniu poniższego kodu JavaScript, co będzie przechowywać zmienna str2?
var str1 = "JavaScript"; var str2 = str1.substring(2,6);
A. nvaScr
B. avaS
C. vaSc
D. vaScri
W przypadku analizy kodu JavaScript kluczowym aspektem jest zrozumienie działania metody substring która służy do wyodrębniania fragmentów łańcuchów znaków. Metoda przyjmuje dwa parametry: indeks początkowy oraz opcjonalny indeks końcowy. W kontekście pytania błędnym podejściem jest niedokładna interpretacja tych indeksów. Pierwsza niepoprawna odpowiedź avaS zakłada że wyodrębniane są znaki od 0 do 3 co jest niezgodne z podanymi indeksami 2 i 6. Druga odpowiedź vaScri zakłada że metoda substring obejmuje znaki aż do indeksu 6 włącznie co jest błędnym zrozumieniem zakresu działania tej metody. Metoda substring kończy wybieranie na znaku poprzedzającym indeks końcowy dlatego indeks 6 nie jest uwzględniany przy wyborze znaków. Kolejna niepoprawna odpowiedź nvaScr próbuje wybrać znaki rozpoczynając od indeksu 1 co jest błędnym startowym punktem dla zakresu 2 do 6. W kontekście dobrych praktyk programistycznych istotnym jest zrozumienie że indeksowanie od zera ma wpływ na rezultaty metod operujących na łańcuchach znaków. Częstym błędem początkujących programistów jest nieuwzględnienie tego faktu co prowadzi do niepoprawnych wyników i błędów logicznych w aplikacjach. Znajomość tych zasad pozwala efektywnie wykorzystywać możliwości języka JavaScript w codziennej pracy programistycznej.
Pytanie 21
Zmienna o typie integer lub int jest w stanie przechowywać
A. znak
B. liczbę rzeczywistą
C. łańcuch znaków
D. liczbę całkowitą
Zmienna typu integer, znana również jako int, jest podstawowym typem danych w wielu językach programowania, takich jak C, C++, Java czy Python. Jej kluczową zaletą jest możliwość przechowywania tylko liczb całkowitych, co czyni ją idealnym wyborem do operacji arytmetycznych, które wymagają precyzyjnego zarządzania wartościami całkowitymi bez części dziesiętnych. Przykłady zastosowania to m.in. przechowywanie ilości przedmiotów w magazynie, zliczanie punktów w grze lub reprezentowanie indeksów w tablicach. W praktyce, użycie zmiennych typu integer umożliwia efektywne wykorzystanie pamięci, ponieważ zajmują one mniej miejsca niż zmienne typu zmiennoprzecinkowego, a ich operacje są wykonywane szybciej. Ponadto, stosowanie zmiennych całkowitych jest zgodne z dobrymi praktykami programowania, które zalecają dobór odpowiednich typów danych do specyficznych potrzeb aplikacji, co zwiększa ich wydajność i czytelność kodu. Warto także zrozumieć, że w kontekście programowania, typ zmiennej determinuje zakres wartości, które można przechowywać, co w przypadku typu integer zwykle wynosi od -2,147,483,648 do 2,147,483,647 w standardzie 32-bitowym, co czyni go wystarczającym dla wielu zastosowań.
Pytanie 22
W językach programowania o układzie strukturalnym, aby przechować dane o 50 uczniach (ich imionach, nazwiskach oraz średniej ocen), konieczne jest zastosowanie
A. klasy z 50 elementami typu tablicowego
B. struktury z 50 elementami o składowych typu tablicowego
C. tablicy z 50 elementami o składowych typu łańcuchowego
D. tablicy z 50 elementami o składowych strukturalnych
Wybór tablicy 50 elementów o składowych strukturalnych jest prawidłowy ze względu na potrzebę przechowywania złożonych danych o uczniach. W tym przypadku, każdy element tablicy powinien reprezentować jednego ucznia i zawierać jego imię, nazwisko oraz średnią ocen. Struktura danych, taka jak struktura, pozwala na grupowanie różnych typów danych w jeden obiekt, co jest zgodne z dobrymi praktykami programowania w językach strukturalnych. Przykładowo, w języku C można zadeklarować strukturę dla ucznia w następujący sposób: `struct Uczen { char imie[50]; char nazwisko[50]; float srednia; };`. Następnie można utworzyć tablicę 50 elementów tej struktury: `struct Uczen uczniowie[50];`. Stosowanie struktur w tym kontekście ułatwia zarządzanie danymi i zwiększa czytelność kodu, co jest szczególnie ważne w przypadku projektów wymagających łatwego dostępu do różnych atrybutów obiektów. Używanie dobrze zdefiniowanych struktur danych jest zgodne z zasadami programowania obiektowego, nawet w językach proceduralnych, i przyczynia się do lepszej organizacji kodu oraz jego skalowalności.
Pytanie 23
W języku PHP zapis // służy do
A. dodawania komentarza wieloliniowego
B. zastosowania operatora dzielenia bez reszty
C. dodawania komentarza jednoliniowego
D. używania tablicy superglobalnej
Znak // w języku PHP jest używany do wstawiania komentarzy jednoliniowych. Oznacza to, że wszystko, co znajduje się po tym znaku na danej linii, zostanie zignorowane przez interpreter PHP. Komentarze są istotnym elementem programowania, ponieważ umożliwiają programistom dodawanie wyjaśnień i notatek do kodu, co znacznie ułatwia jego późniejsze zrozumienie i konserwację. Przykładowo, możesz użyć komentarza jednoliniowego, aby wyjaśnić określoną funkcjonalność w kodzie: // To jest funkcja obliczająca sumę. Warto również pamiętać, że stosowanie komentarzy jest standardową praktyką w branży, która zwiększa czytelność i jakość kodu. Dobrą praktyką jest stosowanie komentarzy, aby wyjaśniać bardziej złożone fragmenty kodu, co wpływa na łatwiejsze współdzielenie pracy w zespołach programistycznych, a także na przyszłe modyfikacje kodu przez innych programistów. Warto zaznaczyć, że PHP obsługuje także komentarze wieloliniowe, które zaczynają się od /* i kończą na */. Jednak dla prostych, jednozdaniowych notatek znak // jest najbardziej odpowiedni.
Pytanie 24
Przy użyciu komendy ALTER TABLE można
A. zmienić dane w rekordach
B. skasować tabelę
C. zmodyfikować strukturę tabeli
D. usunąć dane z rekordu
Kiedy mówimy o poleceniu ALTER TABLE w SQL, to jest to naprawdę ważne narzędzie, które pozwala na zmianę struktury tabeli w bazie danych. Możemy dzięki niemu dodać nowe kolumny, zmienić rodzaj danych w istniejących czy nawet usunąć niepotrzebne kolumny. Na przykład, gdybyśmy chcieli dodać kolumnę 'data_urodzenia' do tabeli 'pracownicy', to musielibyśmy użyć takiego polecenia: ALTER TABLE pracownicy ADD data_urodzenia DATE;. To wszystko jest kluczowe, żeby nasze aplikacje mogły się rozwijać i żeby baza danych spełniała coraz to nowe wymagania. Z mojego doświadczenia wynika, że najlepiej jest zawsze robić kopię zapasową danych przed wprowadzeniem jakichkolwiek zmian. Dobrze by też było testować zmiany w środowisku, które nie jest produkcyjne, zanim coś popsujemy. Warto pamiętać, że niektóre operacje mogą wymagać zablokowania tabeli, co może skutkować tym, że użytkownicy nie będą mogli korzystać z systemu, więc trzeba to mieć na uwadze.
Pytanie 25
Jakie zapytanie umożliwi Administratorowi odebranie uprawnień do przeglądania oraz edytowania danych w bazie gazeta, dla użytkownika redaktor?
A. REVOKE SELECT, UPDATE ON gazeta.* FROM 'redaktor'@'localhost';
B. GRANT SELECT, UPDATE ON gazeta.* TO 'redaktor'@'localhost';
C. REVOKE SELECT, ALTER ON gazeta.* FROM 'redaktor'@'localhost';
D. GRANT SELECT, ALTER ON gazeta.* TO 'redaktor'@'localhost';
Wszystkie pozostałe odpowiedzi są niepoprawne, ponieważ mylą pojęcie przyznawania i odbierania uprawnień. Na przykład, odpowiedź z użyciem GRANT SELECT, UPDATE ON gazeta.* TO 'redaktor'@'localhost'; jest błędna, ponieważ GRANT służy do przyznawania uprawnień, a nie ich odbierania. Użytkownik, który rozważa tę opcję, może mieć fałszywe przekonanie, że jest możliwe przypisanie uprawnień w sytuacji, gdy celem jest ich cofnięcie. Podobnie, odpowiedzi zawierające ALTER, jak REVOKE SELECT, ALTER ON gazeta.* FROM 'redaktor'@'localhost'; wprowadzają dodatkowy zamęt, ponieważ ALTER nie jest związane z przeglądaniem lub aktualizowaniem danych, ale odnosi się do modyfikacji struktury bazy danych. Błędne rozumienie różnic między SELECT, UPDATE i ALTER może prowadzić do poważnych problemów w zarządzaniu bazą danych, na przykład do nieautoryzowanych zmian w strukturze danych. Użytkownicy mogą także popełniać błąd w zakresie lokalizacji użytkownika, co w przypadku odpowiedzi jest określone jako 'redaktor'@'localhost';, co może być mylące w sytuacji, gdy użytkownik jest przypisany do innego hosta. Właściwe zrozumienie i stosowanie uprawnień w bazach danych jest fundamentalne dla ochrony danych, a także dla zapewnienia, że tylko uprawnieni użytkownicy mają dostęp do krytycznych informacji.
Pytanie 26
Przyjmując, że użytkownik Adam nie miał dotychczas żadnych uprawnień, polecenie SQL przyzna mu prawa jedynie do
GRANTCREATE, ALTERONsklep.*TOadam;
A. dodawania i modyfikacji danych w tabeli sklep
B. tworzenia oraz modyfikowania struktury w tabeli sklep
C. dodawania i modyfikacji danych we wszystkich tabelach bazy sklep
D. tworzenia i zmiany struktury wszystkich tabel w bazie sklep
To, co zaznaczyłeś, jest jak najbardziej na miejscu. W tym SQL-u, 'GRANT CREATE, ALTER ON sklep.* TO adam;' dajesz użytkownikowi, czyli adamowi, możliwości tworzenia i zmieniania struktury wszystkich tabel w bazie 'sklep'. Słowo 'CREATE' pozwala mu na tworzenie nowych tabel, a 'ALTER' umożliwia mu wprowadzanie zmian w tych istniejących, na przykład dodawanie czy usuwanie kolumn. Ważne, żeby ogarnąć, że 'sklep.*' oznacza wszystkie tabele w danej bazie, co jest zgodne z dobrymi praktykami w zarządzaniu bazami danych. No bo jakby adam miał ochotę dodać nową tabelę albo zmodyfikować istniejącą, to musi mieć odpowiednie uprawnienia. Przykładem może być sytuacja, gdy administrator daje programiście dostęp do zmian w strukturze tabel, żeby móc dodać nowe funkcje do aplikacji – to naprawdę ważne dla rozwoju systemu.
Pytanie 27
W tabeli artykuly w bazie danych sklepu znajduje się pole o nazwie nowy. Jak należy wykonać kwerendę, aby wypełnić to pole wartościami TRUE dla wszystkich rekordów?
A. UPDATE nowy FROM artykuly VALUE TRUE;
B. INSERT INTO nowy FROM artykuly SET TRUE;
C. INSERT INTO artykuly VALUE nowy=TRUE;
D. UPDATE artykuly SET nowy=TRUE;
Żeby zaktualizować wartości w kolumnie 'nowy' w tabeli 'artykuły' na TRUE, musisz użyć komendy SQL UPDATE. To jest standardowy sposób, żeby zmieniać już istniejące rekordy w tabelach. W tym przypadku komenda 'UPDATE artykuly SET nowy=TRUE;' oznacza, że wszystkie rekordy w tabeli 'artykuły' będą miały pole 'nowy' ustawione na TRUE. To dość prosta i skuteczna operacja, która pozwala na jednolitą zmianę w całej tabeli. Na przykład, jeśli w tabeli 'artykuły' jest 1000 rekordów, to wszystkie z nich dostaną wartość TRUE w polu 'nowy', co może być pomocne, jeśli chcemy oznaczyć nowe produkty. Pamiętaj, żeby robić kopie zapasowe bazy danych przed takimi masowymi zmianami. To może uratować Cię od utraty ważnych danych, gdyby coś poszło nie tak. Użycie tej komendy jest zgodne z ogólnymi zasadami SQL, więc jest to bezpieczny sposób działania dla każdego, kto zarządza bazą danych.
Pytanie 28
W kodzie źródłowym zapisanym w języku HTML wskaż błąd walidacji dotyczący tego fragmentu: ```
CSS
Kaskadowe arkusze stylów (ang. Cascading Style Sheets) to język służący ...```
A. Znacznik br nie może występować wewnątrz znacznika p.
B. Znacznik zamykający /b niezgodny z zasadą zagnieżdżania.
C. Nieznany znacznik h6.
D. Znacznik br nie został poprawnie zamknięty.
Rozważmy błędne koncepcje zawarte w innych odpowiedziach. Wskazanie, że znacznik br nie został poprawnie zamknięty, jest niepoprawne, ponieważ znacznik <br> jest samozamykający i nie wymaga dodatkowego znacznika zamykającego. Często błędem jest próba zamknięcia takich znaczników, co prowadzi do niepotrzebnego zamieszania w kodzie. Dodatkowo, stwierdzenie, że znacznik br nie może występować wewnątrz znacznika p, jest nieprawidłowe. Zgodnie ze standardami HTML, znacznik <br> jest dozwolony wewnątrz <p> i służy do wprowadzenia przerwy linii. Wreszcie, znacznik <h6> jest prawidłowym znacznikiem HTML i jego użycie nie stanowi błędu. Pomyłka ta wynika prawdopodobnie z niepełnej znajomości dostępnych znaczników HTML. Dlatego zawsze warto poszerzać swoją wiedzę na ten temat i regularnie odnosić się do specyfikacji HTML.
Pytanie 29
W znaczniku meta w miejsce kropek należy wpisać
<metaname="description"content="…">
A. informację o dostosowaniu do urządzeń mobilnych.
B. język dokumentu.
C. streszczenie treści strony.
D. nazwę edytora.
Mówiąc, że w znaczniku meta w polu 'content' trzeba umieścić nazwę edytora, to trochę nie na miejscu. Opis strony powinien odnosić się do tego, co właściwie na niej jest, a nie do narzędzia, którym została zrobiona. Tak samo mówienie o definicji języka dokumentu w tym miejscu jest błędne, bo powinno się to robić z atrybutem 'lang' w znaczniku <html>. Wstawianie informacji o wersji mobilnej do pola 'content' znacznika meta też wprowadza w błąd, bo takie rzeczy zazwyczaj są podawane przez odpowiednie style CSS i znacznik <meta name='viewport'>. Często użytkownicy mogą się mylić, myśląc że te informacje można zamieścić w opisie, co jest nieprawda. Każda z tych odpowiedzi pokazuje, że nie do końca rozumiesz, jak działają znaczniki meta i jaka jest ich rola przy tworzeniu stron. Ważne jest, żeby znać gdzie i jak używać różnych atrybutów, bo to wpływa na SEO i na to, jak strona wygląda w wynikach wyszukiwania oraz jakie wartościowe informacje dostarczasz użytkownikom.
Pytanie 30
Przedstawiony fragment kodu PHP ma za zadanie umieścić dane znajdujące się w zmiennych $a, $b, $c w bazie danych, w tabeli dane. Tabela dane zawiera cztery pola, z czego pierwsze to autoinkrementowany klucz główny. Które z poleceń powinno być przypisane do zmiennej $zapytanie?
C. INSERT INTO dane VALUES (NULL, '$a', '$b', '$c');
D. SELECT NULL, '$a', '$b', '$c' FROM dane;
Właściwe polecenie to 'INSERT INTO dane VALUES (NULL, '$a', '$b', '$c');'. Użycie NULL w pierwszym polu pozwala na automatyczne ustawienie wartości klucza głównego, co jest zgodne z zasadą autoinkrementacji w bazach danych. Wartości zmiennych $a, $b i $c są wstawiane do kolejnych pól tabeli, co jest standardową praktyką w przypadku dodawania nowych rekordów do bazy danych. Dobrą praktyką jest również stosowanie przygotowanych zapytań, aby zminimalizować ryzyko ataków typu SQL injection. Można to osiągnąć za pomocą funkcji mysqli_prepare, co zwiększa bezpieczeństwo aplikacji. W kontekście standardów branżowych, PostgreSQL oraz MySQL stosują podobne zasady dotyczące wstawiania danych, co czyni tę wiedzę uniwersalną dla różnych systemów zarządzania bazami danych. Warto również zrozumieć, że wstawianie danych bezpośrednio przy użyciu zmiennych bez walidacji może prowadzić do błędów, dlatego zaleca się ich odpowiednie przetwarzanie przed wykonaniem zapytania.
Pytanie 31
Jakie są odpowiednie kroki w odpowiedniej kolejności, które należy podjąć, aby nawiązać współpracę pomiędzy aplikacją internetową po stronie serwera a bazą danych SQL?
A. nawiązanie połączenia z serwerem baz danych, wybór bazy, zapytanie do bazy - wyświetlane na stronie WWW, zamknięcie połączenia
B. wybór bazy danych, nawiązanie połączenia z serwerem baz danych, zapytanie do bazy - wyświetlane na stronie WWW, zamknięcie połączenia
C. wybór bazy, zapytanie do bazy, nawiązanie połączenia z serwerem baz danych, wyświetlenie na stronie WWW, zamknięcie połączenia
D. zapytanie do bazy, wybór bazy, wyświetlenie na stronie WWW, zamknięcie połączenia
Analizując niepoprawne odpowiedzi, można zauważyć, że każda z nich zawiera fundamentalne błędy w kolejności operacji. W przypadku pierwszej odpowiedzi, zaczynanie od zapytania do bazy danych bez wcześniejszego nawiązania połączenia z serwerem jest nie tylko niepraktyczne, ale wręcz niemożliwe. System nie jest w stanie wykonać jakiegokolwiek zapytania, jeśli nie istnieje aktywne połączenie, co prowadzi do błędów wykonania. W drugiej odpowiedzi również występuje błąd, polegający na wysyłaniu zapytania przed wybraniem bazy danych. W rzeczywistości, aby system mógł poprawnie zrealizować zapytanie, musi najpierw wiedzieć, z jaką bazą ma do czynienia. Ostatnia z niepoprawnych odpowiedzi, która sugeruje wybór bazy danych przed nawiązaniem połączenia, również jest błędna, ponieważ nie można wybrać bazy bez aktywnego połączenia z serwerem. W praktyce, każda z tych odpowiedzi nie uwzględnia kluczowych zasad dotyczących zarządzania połączeniami z bazami danych, takich jak zasady dotyczące transakcji oraz efektywnego zarządzania zasobami, co jest niezbędne w kontekście wydajnych aplikacji internetowych.
Pytanie 32
W języku JavaScript przedstawiona poniżej definicja jest definicją var imiona=["Anna", "Jakub", "Iwona", "Krzysztof"];
A. tablicy.
B. obiektu.
C. klasy.
D. kolekcji.
W języku JavaScript definicja var imiona=["Anna", "Jakub", "Iwona", "Krzysztof"]; przedstawia tablicę, która jest jednym z fundamentalnych typów danych w tym języku. Tablice są używane do przechowywania zbiorów danych w sposób uporządkowany. W tym przypadku tablica imiona przechowuje cztery stringi, każdy reprezentujący imię. Wartością dodaną tablicy jest możliwość dostępu do poszczególnych elementów za pomocą indeksów, które zaczynają się od zera. Na przykład, imiona[0] zwróci \"Anna\", a imiona[1] zwróci \"Jakub\". W praktyce tablice są niezwykle przydatne w programowaniu, ponieważ pozwalają na łatwe zarządzanie i manipulację danymi. Dobrą praktyką jest używanie tablic do przechowywania związków danych, co umożliwia ich efektywne przetwarzanie i iterację za pomocą pętli, co zwiększa czytelność i organizację kodu. Warto również zaznaczyć, że tablice w JavaScript są obiektami, co daje dodatkowe możliwości manipulacji, takie jak metody tablicowe (np. push, pop, map, filter) do operacji na zbiorach danych. Poznanie i zrozumienie tablic jest kluczowe dla każdego programisty, ponieważ są one podstawą wielu algorytmów i struktur danych."
Pytanie 33
Celem testów wydajnościowych jest ocena
A. stopnia, w jakim system lub moduł spełnia wymagania dotyczące wydajności
B. zdolności programu do funkcjonowania w sytuacjach, gdy system działa niepoprawnie
C. ciągu zdarzeń, w którym prawdopodobieństwo danego zdarzenia zależy tylko od wyniku zdarzenia wcześniejszego
D. zdolności programu do funkcjonowania w sytuacjach, gdy sprzęt działa niepoprawnie
Analizując pozostałe odpowiedzi, można zauważyć, że żadna z nich nie odnosi się bezpośrednio do istoty testów wydajnościowych. Pierwsza z nich sugeruje, że testy te mają na celu sprawdzenie zdolności oprogramowania do działania w warunkach wadliwej pracy sprzętu. Chociaż testowanie pod kątem awarii sprzętowych jest istotnym elementem inżynierii oprogramowania, to nie jest to kluczowy aspekt testów wydajnościowych. Testy wydajnościowe koncentrują się na ocenie wydajności, a nie na sprawdzaniu reakcji systemu na uszkodzenia sprzętu. Druga odpowiedź dotyczy zdolności oprogramowania do działania w warunkach wadliwej pracy systemu, co także jest ważnym zagadnieniem w kontekście testowania, lecz nie jest to celem testów wydajnościowych. Testowanie odporności i niezawodności systemu jest częścią testowania funkcjonalnego, a nie wydajnościowego. Z kolei ostatnia z propozycji odnosi się do analizy ciągu zdarzeń, w którym prawdopodobieństwo każdego zdarzenia zależy jedynie od wyniku poprzedniego. To zagadnienie dotyczy bardziej teorii prawdopodobieństwa i statystyki, a nie bezpośrednio wydajności oprogramowania. Testy wydajnościowe skupiają się na mierzeniu i optymalizacji parametrów, a nie na analizie statystycznej zdarzeń w kontekście ich prawdopodobieństwa.
Pytanie 34
Po wykonaniu poniższego kodu JavaScript, który operuje na wcześniej przygotowanej tablicy liczby, w zmiennej wynik znajduje się suma
var wynik = 0; for (i = 0; i < 100; i++) if (liczby[i] % 2 == 0) wynik += liczby[i];
A. nieparzystych elementów tablicy
B. dodatnich elementów tablicy
C. parzystych elementów tablicy
D. wszystkich elementów tablicy
Kod analizuje tablicę liczby i sumuje wyłącznie te elementy, które są parzyste. Nie można zatem mówić o sumowaniu nieparzystych czy wszystkich elementów tablicy. Warunek liczby[i] % 2 == 0 jednoznacznie wskazuje na sumowanie wyłącznie parzystych wartości – reszta z dzielenia przez 2 równa 0 jednoznacznie identyfikuje liczbę jako parzystą. W kontekście sumowania wszystkich elementów, kod nie spełnia tej funkcji, gdyż wykorzystuje warunek ograniczający sumowanie do parzystych liczb. Rozważania o sumowaniu wszystkich elementów lub tylko dodatnich nie znajdują uzasadnienia w analizowanym kodzie. Częstym błędem może być mylenie operacji logicznych i warunkowych w pętli, co prowadzi do niepoprawnych interpretacji zadania. W praktyce, prawidłowe zrozumienie i zastosowanie operatorów warunkowych, takich jak modulo, jest niezbędne w programowaniu, szczególnie przy operacjach na tablicach i dużych zestawach danych. Warunki, jak ten zastosowany w kodzie, umożliwiają precyzyjne filtrowanie danych, co jest kluczowe w wielu aplikacjach, w tym w analizie danych czy automatyzacji procesów. Zrozumienie tych mechanizmów jest fundamentalne dla programisty, zarówno w kontekście wydajności, jak i poprawności działania algorytmów.
Pytanie 35
Jakie polecenie wykonane w systemowej konsoli umożliwi przywrócenie bazy danych?
A. mysql -u root -p baza > kopia.sql
B. mysql -u root -p baza < kopia.sql
C. mysqldump -u root -p baza < kopia.sql
D. mysqldump -u root -p baza > kopia.sql
Wszystkie inne odpowiedzi są niepoprawne, ponieważ z użyciem niewłaściwych poleceń z systemu MySQL. Pierwsze z tych poleceń, zamiast przywracać bazę danych, tworzy jej kopię zapasową, co nie odpowiada na zadane pytanie. Użycie 'mysqldump' z parametrami '-u root -p baza > kopia.sql' jest sposobem na eksport danych z bazy do pliku SQL, a nie na ich import. Kolejne polecenie sugeruje zastosowanie 'mysqldump' w kontekście przywracania, co jest również błędne, ponieważ 'mysqldump' jest narzędziem służącym do zrzutów, a nie importu. Z kolei ostatnie polecenie 'mysql -u root -p baza > kopia.sql' ponownie nie wykonuje przywracania, lecz zapisuje dane z bazy danych do pliku, co jest odwrotnością oczekiwanej operacji. W praktyce, błędne zastosowanie tych poleceń może prowadzić do poważnych konsekwencji, takich jak utrata danych czy niewłaściwe zarządzanie bazą danych. Dlatego kluczowe jest zrozumienie roli każdego z narzędzi dostępnych w MySQL oraz ich poprawne zastosowanie w różnych scenariuszach administracyjnych.
Pytanie 36
Do którego akapitu przypisano podaną właściwość stylu CSS? border-radius: 20%;
A. Rys. A
B. Rys. D
C. Rys. C
D. Rys. B
Właściwość CSS border-radius służy do zaokrąglania rogów elementu na stronie internetowej. W przypadku wartości procentowej jak 20% zaokrąglenie jest obliczane w stosunku do wymiarów elementu co pozwala na uzyskanie proporcjonalnego wyglądu niezależnie od rozmiaru ramki. Wybranie odpowiedzi Rys. B jest poprawne ponieważ widoczny jest tam efekt zaokrąglonych rogów co jednoznacznie wskazuje na zastosowanie border-radius. Takie stylizacje są powszechnie używane w projektowaniu nowoczesnych interfejsów użytkownika aby nadać im bardziej miękki i przyjazny wygląd. Dobre praktyki projektowe zalecają umiarkowane stosowanie zaokrągleń aby nie przesadzić z efektami wizualnymi co mogłoby pogorszyć czytelność i funkcjonalność. Warto również pamiętać o aspekcie responsywności – używanie wartości procentowych pozwala na lepsze dostosowanie się do różnych rozdzielczości ekranów co jest kluczowe w nowoczesnym web designie. Dzięki border-radius można także tworzyć zaawansowane efekty graficzne łącząc go z innymi właściwościami CSS jak cienie czy gradienty co pozwala na osiągnięcie atrakcyjnych wizualnie elementów bez potrzeby użycia obrazów.
Pytanie 37
Aby przekształcić obraz z formatu JPEG do PNG bez utraty jakości, tak aby kolor biały w oryginalnym obrazie został zastąpiony przezroczystością w wersji docelowej, należy najpierw
A. dodać kanał alfa
B. usunięcie gumką wszystkich białych miejsc
C. załadować obraz do programu do edycji grafiki wektorowej
D. obniżyć rozdzielczość obrazu
Żeby zmienić obrazek z formatu JPEG na PNG i zachować przezroczystość tam, gdzie wcześniej był biały kolor, ważny krok to dodanie kanału alfa. To w zasadzie taka dodatkowa warstwa w obrazie, która mówi, które piksele mają być przezroczyste. JPEG nie umie obsługiwać przezroczystości, więc białe obszary będą się pokazywać jako nieprzezroczyste. Jak już dodasz ten kanał alfa, możesz ustawić przezroczystość dla białych pikseli, co pozwoli na ich ukrycie lub zamianę na przezroczystość w końcowym obrazku. Na przykład, w programach jak Adobe Photoshop można użyć narzędzia do zaznaczania kolorów, żeby wybrać wszystkie białe piksele i potem je usunąć, zostawiając tylko przezroczystość. W ten sposób dostajesz efekt, którego chcesz w obrazie PNG, co jest zgodne z dobrą praktyką w obróbce grafiki i pomaga utrzymać wysoką jakość obrazu bez żadnych strat.
Pytanie 38
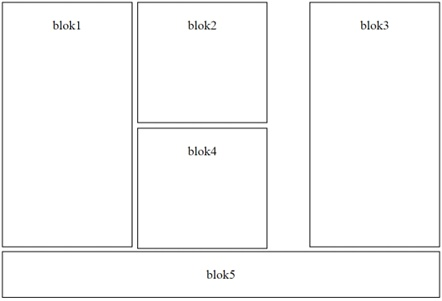
Na przedstawionej grafice znajduje się struktura sekcji dla witryny internetowej. Przyjmując, że blok5 nie ma przypisanej szerokości, a bloki są określone w dokumencie HTML w kolejności ich numeracji, jak powinno wyglądać zdefiniowanie opływania?
Właściwe użycie float w CSS jest kluczowe do tworzenia układów stron. W pierwszej propozycji zastosowano float: left; dla bloków 1, 2, 4 oraz float: right; dla bloków 3 i 5, co jest niepoprawne, ponieważ blok 5 powinien być odseparowany od pozostałych poprzez clear: both;, aby zająć całą szerokość strony. W drugiej odpowiedzi, chociaż float: right; dla bloków 1, 2, 3, 4 może wydawać się poprawne dla niektórych stylów, blok 5 z clear: right; nie będzie działał, ponieważ nie uwzględnia float: left, które ma zastosowanie w układzie. Ostatnia odpowiedź używa float: center;, co jest nieprawidłowe, ponieważ w CSS nie istnieje taka właściwość. Elementy można centrować za pomocą innych metod, ale nie za pomocą float. Ponadto, przypisanie clear dla bloku 5 jest poprawne, ale pozostałe ustawienia float dla bloków są błędne i niezgodne z przedstawionym układem. Konsekwentne błędy często wynikają z braku zrozumienia, jak właściwości float i clear współdziałają w kontekście modelu pudełkowego w CSS.
Pytanie 39
Baza danych 6-letniej szkoły podstawowej zawiera tabelę szkola z polami: imie, nazwisko oraz klasa. Uczniowie z klas 1-5 przeszli do wyższej klasy. Jakie polecenie należy użyć, aby zwiększyć wartość w polu klasa o 1?
A. UPDATE szkola SET klasa=klasa+1 WHERE klasa>=1 AND klasa <=5
B. SELECT szkola FROM klasa=klasa+1 WHERE klasa >=1 AND klasa <=5
C. SELECT nazwisko, imie FROM klasa=klasa+1 WHERE klasa>1 OR klasa <5
D. UPDATE nazwisko, imie SET klasa=klasa+1 WHERE klasa>1 OR klasa<5
W analizie błędnych odpowiedzi należy zwrócić uwagę na nieprawidłowości w składni i logice zapytań. Pierwsza odpowiedź sugeruje użycie 'UPDATE nazwisko, imie SET klasa=klasa+1 WHERE klasa>1 OR klasa<5;', co jest niepoprawne, ponieważ 'UPDATE' powinno odnosić się do całej tabeli, a nie do pojedynczych pól. Ponadto warunki w klauzuli 'WHERE' są zbyt ogólne, co skutkowałoby aktualizacją uczniów, którzy nie zdali do kolejnej klasy. Druga odpowiedź zawiera poprawną strukturę, ale użycie 'SELECT szkola FROM klasa=klasa+1 WHERE klasa >=1 AND klasa <=5;' jest błędne, gdyż 'SELECT' nie jest odpowiednie do aktualizacji danych - powinno być użyte 'UPDATE'. Ostatnia propozycja również myli pojęcia, stosując 'SELECT' zamiast 'UPDATE', co skutkuje próbą odczytania danych, zamiast ich aktualizacji. Typowym błędem myślowym jest mylenie tych dwóch komend w SQL, co prowadzi do nieporozumień w zakresie manipulacji danymi. Kluczowe jest zrozumienie, że 'UPDATE' jest używane do zmiany istniejących rekordów, podczas gdy 'SELECT' służy do pobierania danych. Aby uniknąć takich błędów, ważne jest, aby zrozumieć funkcje i zastosowania różnych poleceń SQL oraz praktykować ich wykorzystanie w rzeczywistych scenariuszach.
Pytanie 40
Jakie wartości zostaną wyświetlone kolejno w wyniku wykonania podanego skryptu?
<script language = "JavaScript"> var x = 1; var y; ++y; document.write(++x); document.write(" "); document.write(x--); document.write(" "); document.write(x); </script>
A. 1 2 1
B. 1 2 2
C. 2 1 1
D. 2 2 1
Skrypt operuje na zmiennej x używając zarówno preinkrementacji jak i postdekrementacji co może być mylące jeśli nie jest się zaznajomionym z ich działaniem. W przypadku preinkrementacji ++x wartość zmiennej x jest najpierw zwiększana zanim zostanie wykorzystana w dalszym wyrażeniu. To jest kluczowe ponieważ oznacza że już przy pierwszym wypisaniu wartość x to 2 co jest często błędnie interpretowane jako 1 jeśli nie uwzględni się preinkrementacji. Z kolei postdekrementacja x-- oznacza że obecna wartość zmiennej jest używana zanim zostanie ona zmniejszona. To często jest źródłem błędów logicznych gdyż programista może oczekiwać że wartość zmiennej została już zaktualizowana. W efekcie druga wartość jest również 2 ponieważ dekrementacja następuje po użyciu wartości w wyrażeniu a dopiero trzecia instrukcja wypisuje wynik dekrementacji czyli 1. Zrozumienie tych mechanizmów jest kluczowe w kontekście pisania wydajnego i poprawnego kodu zwłaszcza w językach takich jak JavaScript gdzie operacje na zmiennych są powszechne. Warto zatem zwrócić uwagę na różnicę między pre- a post- operacjami aby uniknąć potencjalnych błędów w logice aplikacji i lepiej zarządzać przepływem danych w programach. Dobre praktyki programistyczne zalecają również konsystencję w korzystaniu z tych operatorów co pomaga w utrzymaniu czytelności i zrozumiałości kodu przez współpracowników i samego autora post factum. Tego rodzaju błędy należą do typowych wśród początkujących programistów i podkreślają znaczenie dokładnego testowania i dokumentowania kodu dla zapewnienia jego niezawodności i poprawności działania w różnorodnych kontekstach środowiskowych i użytkowych. Weryfikacja takich operacji w trakcie testów jednostkowych pozwala na wcześniejsze wykrycie i korektę błędów logicznych co jest zgodne z najlepszymi praktykami w inżynierii oprogramowania. Przy tym podejściu zmniejsza się również ryzyko nieoczekiwanych zachowań aplikacji w środowiskach produkcyjnych co może mieć kluczowe znaczenie w przypadku aplikacji o krytycznym znaczeniu dla biznesu.
Strona wykorzystuje pliki cookies do poprawy doświadczenia użytkownika oraz analizy ruchu. Szczegóły
Polityka plików cookies
Czym są pliki cookies?
Cookies to małe pliki tekstowe, które są zapisywane na urządzeniu użytkownika podczas przeglądania stron internetowych. Służą one do zapamiętywania preferencji, śledzenia zachowań użytkowników oraz poprawy funkcjonalności serwisu.
Jakie cookies wykorzystujemy?
Niezbędne cookies - konieczne do prawidłowego działania strony
Funkcjonalne cookies - umożliwiające zapamiętanie wybranych ustawień (np. wybrany motyw)
Analityczne cookies - pozwalające zbierać informacje o sposobie korzystania ze strony
Jak długo przechowujemy cookies?
Pliki cookies wykorzystywane w naszym serwisie mogą być sesyjne (usuwane po zamknięciu przeglądarki) lub stałe (pozostają na urządzeniu przez określony czas).
Jak zarządzać cookies?
Możesz zarządzać ustawieniami plików cookies w swojej przeglądarce internetowej. Większość przeglądarek domyślnie dopuszcza przechowywanie plików cookies, ale możliwe jest również całkowite zablokowanie tych plików lub usunięcie wybranych z nich.