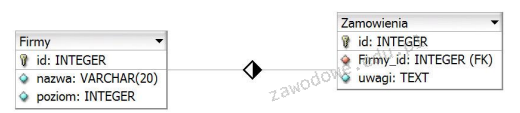
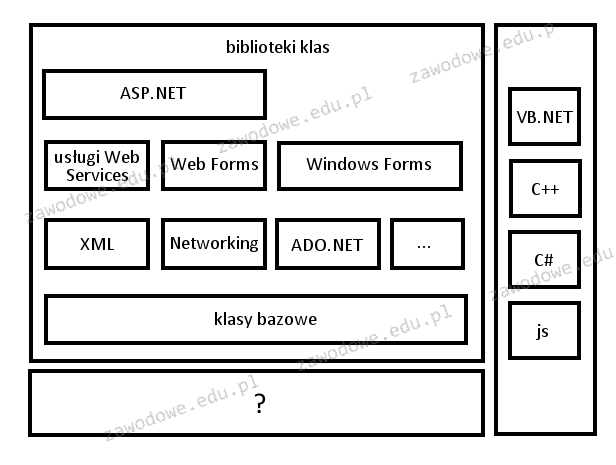
Pytanie 1
W języku PHP zmienna typu float może przyjmować wartości
A. jedynie liczby całkowite
B. wartości logiczne
C. wartości nieliczbowe
D. wartości zmiennoprzecinkowe
W języku PHP zmienne typu float są używane do reprezentowania liczb zmiennoprzecinkowych, co oznacza, że mogą przechowywać zarówno wartości całkowite, jak i wartości z częścią ułamkową. Typ float w PHP jest szczególnie przydatny w sytuacjach, gdzie precyzyjne obliczenia są niezbędne, na przykład w aplikacjach finansowych, gdzie obliczenia z użyciem pieniędzy wymagają uwzględnienia centów. W praktyce, operacje na zmiennych typu float mogą obejmować dodawanie, odejmowanie, mnożenie oraz dzielenie. Warto również zauważyć, że PHP obsługuje zarówno liczby w formacie dziesiętnym, jak i w notacji naukowej. Dobrą praktyką jest używanie funkcji takich jak round() do zaokrąglania wyników obliczeń zmiennoprzecinkowych, aby uniknąć problemów z precyzją, które mogą występować w wyniku ograniczeń reprezentacji liczb zmiennoprzecinkowych w pamięci komputera. W dokumentacji PHP, typ float jest jasno zdefiniowany jako liczba zmiennoprzecinkowa, co podkreśla jego kluczową rolę w różnych zastosowaniach programistycznych. Zrozumienie tego typu zmiennych jest fundamentem dla efektywnego programowania w PHP.