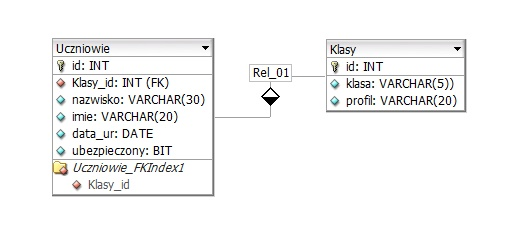
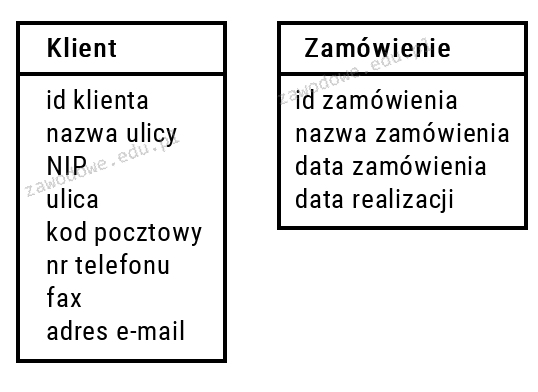
Pytanie 1
Jakie zadania programistyczne należy wykonać na serwerze?
A. Weryfikacja danych wprowadzonych do pola tekstowego na bieżąco
B. Zmiana stylu HTML na stronie spowodowana ruchem kursora
C. Ukrywanie i wyświetlanie elementów strony w zależności od aktualnej pozycji kursora
D. Zapisanie danych pozyskanych z aplikacji internetowej w bazie danych
Zapisanie danych pobranych z aplikacji internetowej w bazie danych to zadanie, które powinno być wykonywane po stronie serwera ze względów bezpieczeństwa, integralności danych oraz zarządzania zasobami. Serwer jest odpowiedzialny za przechowywanie informacji, które mogą być wykorzystywane przez wielu użytkowników, co wymaga centralizacji ich przetwarzania. W przypadku aplikacji internetowych, dane są często przesyłane z klienta (przeglądarki) do serwera, gdzie są walidowane oraz zapisywane w bazach danych. Na przykład, gdy użytkownik rejestruje się w aplikacji, jego dane osobowe są wysyłane do serwera, który sprawdza poprawność tych informacji i zapisuje je w bazie danych. Właściwe implementacje powinny stosować bezpieczne połączenia (np. HTTPS), a także techniki, takie jak sanitizacja danych, aby unikać ataków typu SQL Injection. Dobrą praktyką jest także stosowanie ORM (Object-Relational Mapping), co umożliwia łatwiejsze zarządzanie danymi i ich relacjami. Przechowywanie danych po stronie serwera pozwala na efektywne zarządzanie zasobami i umożliwia późniejsze przetwarzanie informacji w sposób zorganizowany i bezpieczny.