Pytanie 1
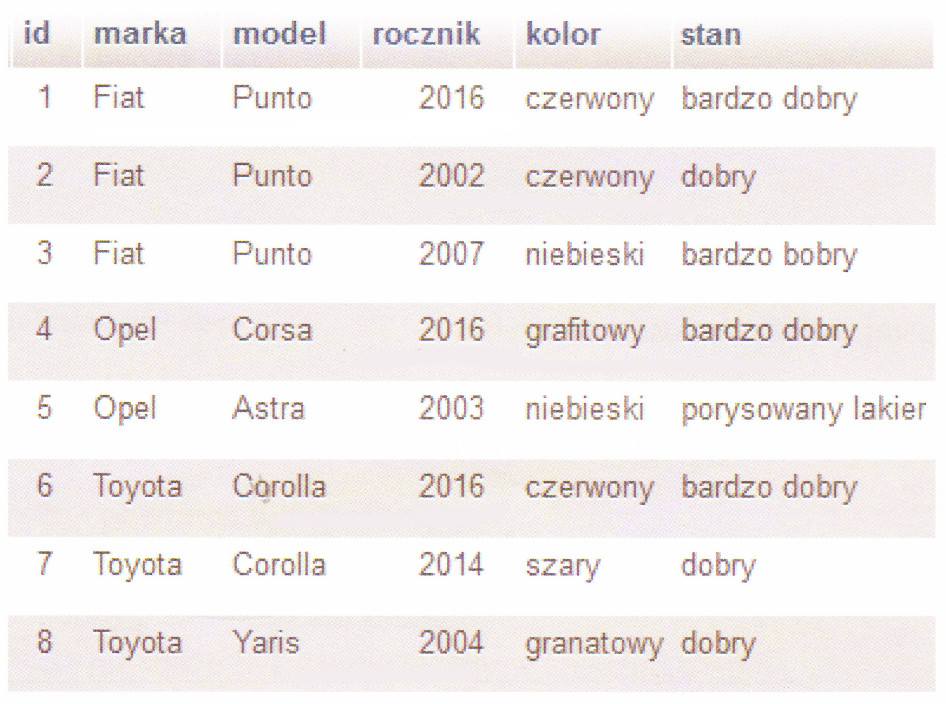
Na podstawie relacji przedstawionej na ilustracji, można stwierdzić, że jest to relacja
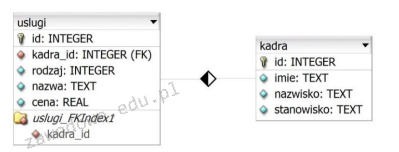
A. wiele do wielu pomiędzy kluczami głównymi obu tabel
B. jeden do jednego, gdzie obie tabele mają przypisane klucze obce
C. jeden do wielu, gdzie kluczem obcym jest pole w tabeli kadra
D. jeden do wielu, gdzie kluczem obcym jest pole w tabeli uslugi
Relacja jeden do wielu, gdzie kluczem obcym jest pole w tabeli uslugi, jest poprawna, ponieważ reprezentuje typową praktykę w projektowaniu baz danych, gdzie wiele rekordów w jednej tabeli (uslugi) jest powiązanych z jednym rekordem w innej tabeli (kadra). W tym przypadku, kolumna kadra_id w tabeli uslugi pełni rolę klucza obcego, który wskazuje na klucz główny (id) w tabeli kadra. Takie podejście jest szeroko stosowane w zarządzaniu relacjami pomiędzy danymi, umożliwiając efektywne przechowywanie i odwoływanie się do powiązanych rekordów. Przykładowo, w systemie usługowym, jedna osoba może być odpowiedzialna za wiele różnych usług, co jest wizualizowane przez tę konstrukcję. W praktyce pozwala to na łatwe aktualizacje danych kadry bez konieczności zmian w tabeli usług, co jest zgodne z zasadami normalizacji danych i zwiększa spójność oraz integralność danych. Tego typu relacje są fundamentem dla operacji typu JOIN w SQL, które umożliwiają łączenie danych z różnych tabel na podstawie wspólnych wartości kluczy obcych, co jest kluczowe dla wydajnego przetwarzania zapytań w relacyjnych bazach danych.