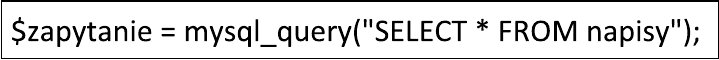Pytanie 1
Jak należy prawidłowo udokumentować wzorcowanie pola nazwa we fragmencie kodu JavaScript?
| function validateForm(Form) { reg=/^\[1-9\]*[A-ZŻŹĘĄĆŚÓŁŃ]{1}[a-zżźćńółęąś]{2,}$/; wyn = Form.nazwa.value.match(reg); if (wyn == null) { alert("Proszę podać poprawną nazwę"); return false; } return true; } |
A. /* Pole nazwa musi składać się w kolejności: z ciągu cyfr (z wyłączeniem 0), następnie dużej litery i dwóch małych liter. */
B. /* Pole nazwa powinno składać się w kolejności: z ciągu cyfr (z wyłączeniem 0), następnie dużej litery i ciągu małych liter. */
C. /* Pole nazwa może zawierać dowolny ciąg cyfr (z wyłączeniem 0), następnie musi zawierać dużą literę i ciąg minimum dwóch małych liter. */
D. /* Pole nazwa może składać się z dowolnego ciągu cyfr (z wyłączeniem 0), małych i dużych liter. */
Odpowiedź druga jest poprawna, ponieważ dokładnie opisuje wzorzec walidacji użyty w kodzie JavaScript. Wyrażenie regularne określa, że pole nazwa może zaczynać się od dowolnej liczby cyfr od 1 do 9, co oznacza, że cyfra 0 jest wykluczona, co jest zgodne z opisem. Następnie musi wystąpić jedna duża litera, co jest również zgodne z wymogiem wzorca. Kolejnym wymogiem jest wystąpienie co najmniej dwóch małych liter, co także jest zgodne z przedstawionym wzorcem. Poprawna i precyzyjna dokumentacja kodu ma kluczowe znaczenie dla utrzymania oraz dalszego rozwoju oprogramowania. Dobrze udokumentowane wyrażenia regularne pozwalają na lepsze zrozumienie logiki walidacji i ułatwiają pracę zespołom deweloperskim. Warto również zauważyć, że stosowanie wyrażeń regularnych w walidacji danych wejściowych jest standardową praktyką w branży IT, szczególnie w aplikacjach webowych, gdzie dane użytkowników wymagają szczegółowego sprawdzania pod kątem poprawności i bezpieczeństwa. Dzięki temu można uniknąć potencjalnych błędów i ataków wynikających z niewłaściwie przetworzonych danych.