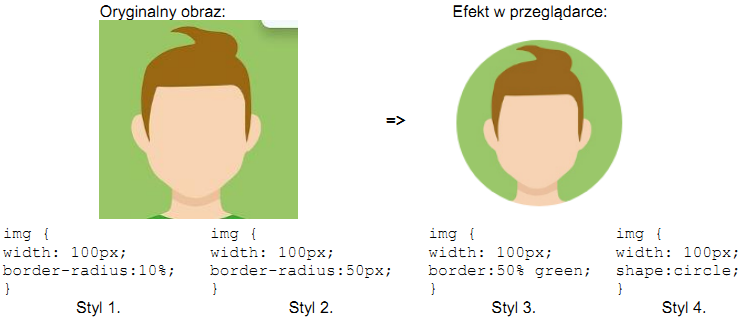
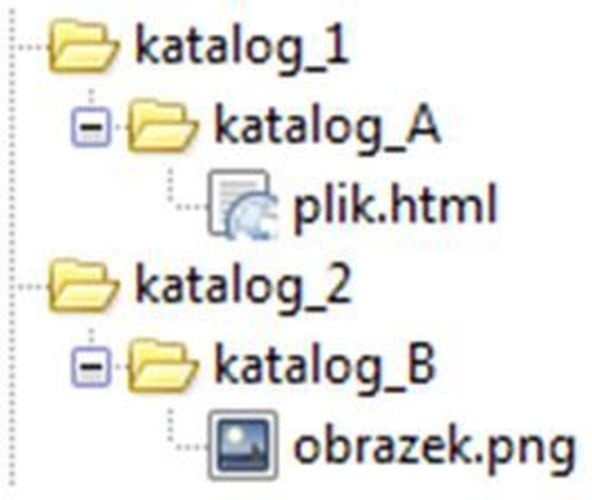
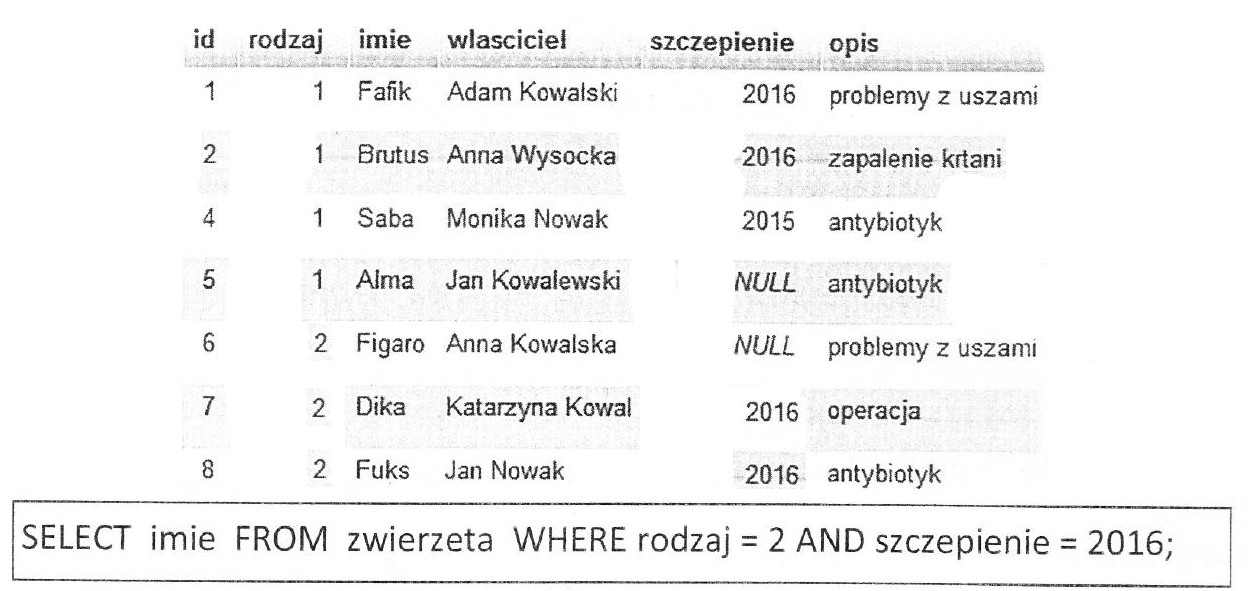
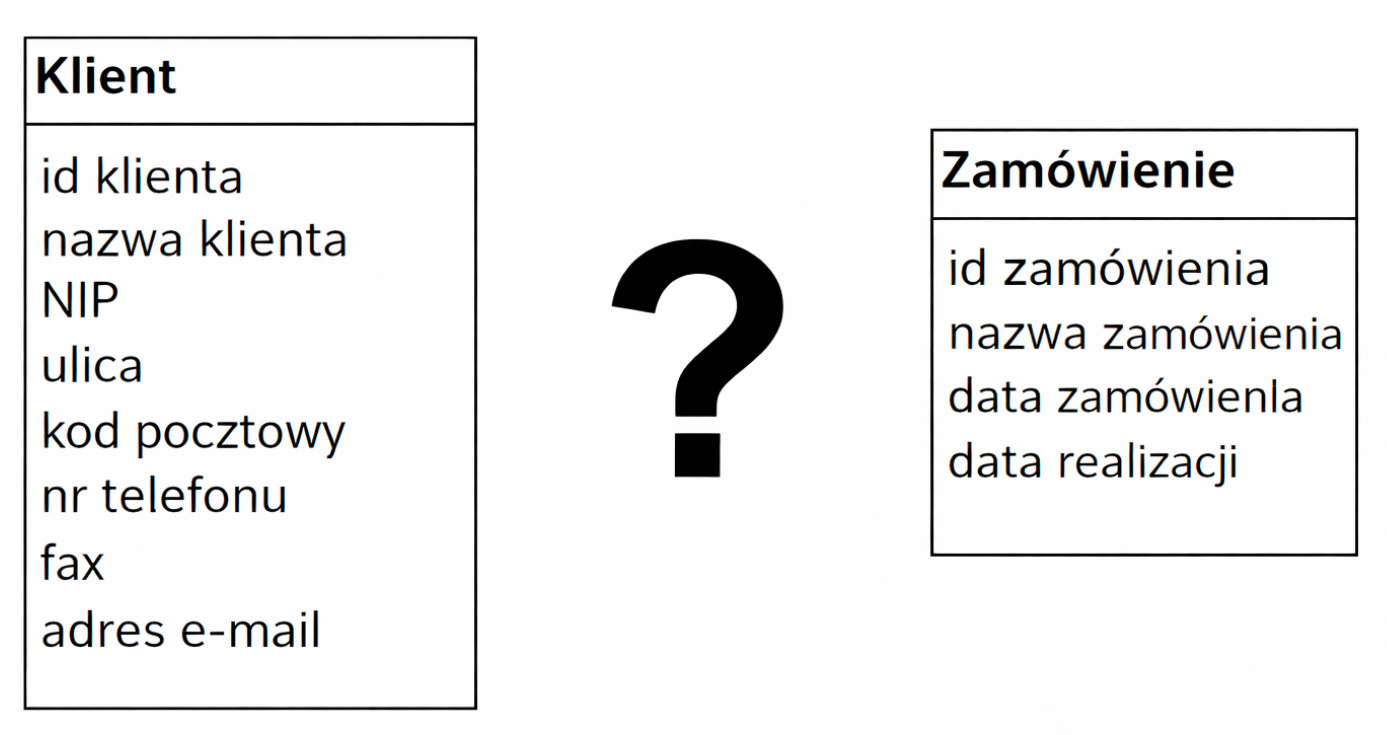
Pytanie 1
Parkowanie domeny to proces, który polega na
A. zmianie właściciela domeny poprzez cesję
B. stworzeniu strefy domeny i wskazaniu serwerów DNS
C. dodaniu aliasu CNAME dla domeny
D. nabyciu nowej domeny
Zakup nowej domeny nie jest tożsamy z parkowaniem domeny, ponieważ odnosi się do etapu, w którym użytkownik nabywa prawo do jej używania. Chociaż zakupienie domeny jest pierwszym krokiem do jej późniejszego używania, nie wiąże się bezpośrednio z jej parkowaniem. Wprowadzenie aliasu CNAME dla domeny również nie jest związane z parkowaniem. Alias CNAME jest używany do przekierowywania zapytań DNS z jednej domeny na inną i może być stosowany dopiero po skonfigurowaniu strefy. Zmiana abonenta domeny przez cesję dotyczy transferu praw do domeny, co również nie ma związku z jej parkowaniem. Właściwe parkowanie domeny polega na jej skonfigurowaniu w sposób umożliwiający jej zarządzanie, co nie jest realizowane przez same zakupy, aliasy czy cesje. Często mylenie tych koncepcji prowadzi do dezorientacji w zakresie zarządzania domenami. Aby prawidłowo parkować domenę, konieczne jest zrozumienie roli serwerów DNS oraz strefy domeny, co jest kluczowe dla przyszłego wykorzystania domeny w Internecie.