Pytanie 1
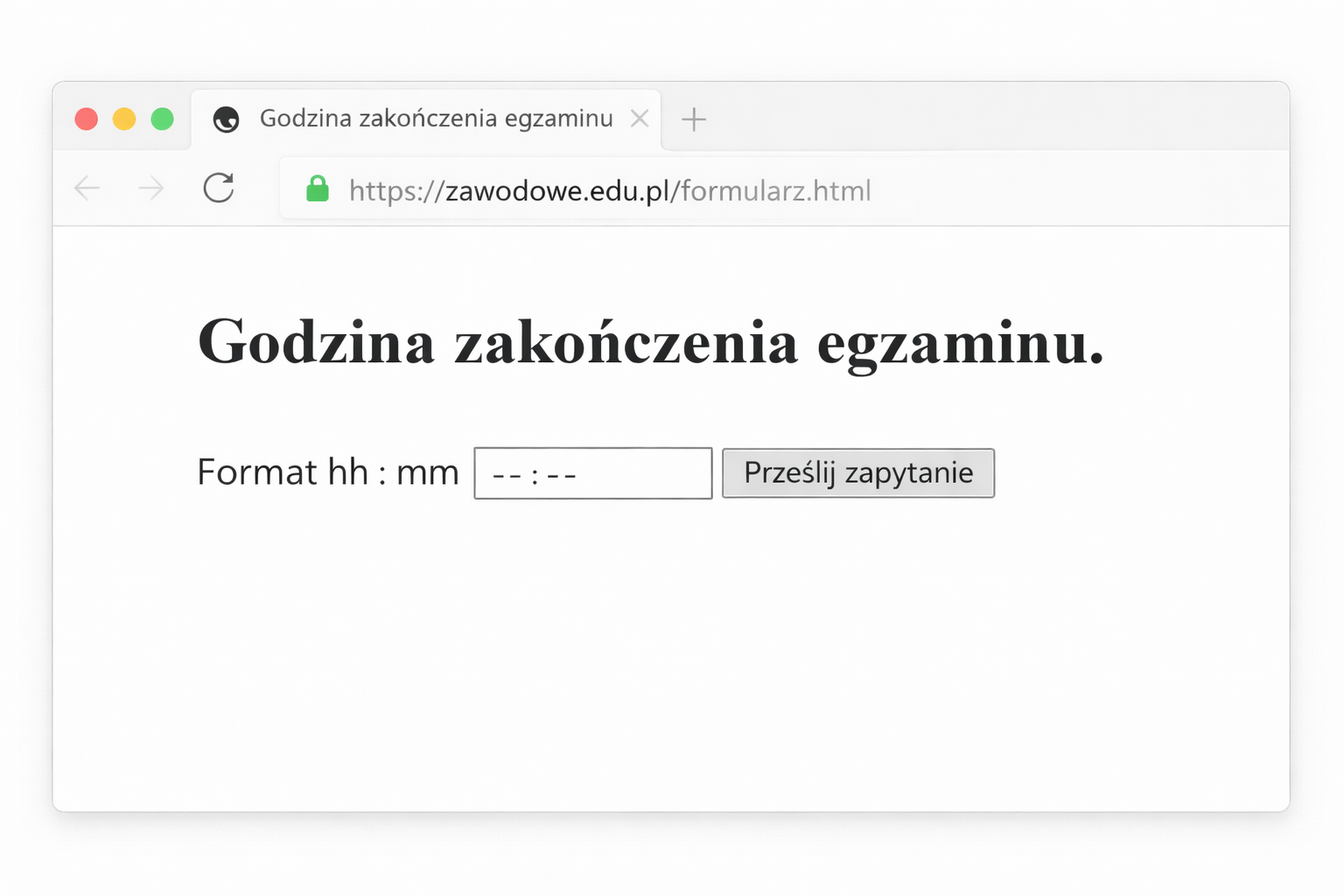
Co chce osiągnąć poniższe zapytanie MySQL?
| ALTER TABLE ksiazki MODIFY tytul VARCHAR(100) NOT NULL; |
A. Zmienić nazwę kolumny w tabeli ksiazki
B. Usunąć kolumnę tytul z tabeli ksiazki
C. Dodać do tabeli ksiazki kolumnę tytul
D. Zmienić typ kolumny w tabeli ksiazki
Rozważając inne odpowiedzi, warto zrozumieć, dlaczego nie są poprawne. Dodanie kolumny do tabeli w SQL realizowane jest za pomocą polecenia ADD, co różni się od użytego tutaj MODIFY. Polecenie ADD jest używane, gdy chcemy wprowadzić nową kolumnę, której wcześniej w tabeli nie było. Z kolei usunięcie kolumny wymaga użycia DROP COLUMN, co także odbiega od przedstawionego polecenia. Polecenie DROP COLUMN jest bardziej destrukcyjne, ponieważ usuwa całą kolumnę i jej dane. Zmiana nazwy kolumny w SQL zazwyczaj wymaga użycia polecenia RENAME, które służy do zmiany nazewnictwa kolumn lub tabel. W zależności od systemu zarządzania bazą danych (DBMS), składnia może się różnić, ale w MySQL często używa się RENAME COLUMN. Błędne rozumienie tych poleceń często wynika z niewystarczającego zapoznania się z dokumentacją danego DBMS, co może prowadzić do zastosowania nieodpowiednich poleceń. Praktyka i znajomość standardów SQL pomagają uniknąć takich pomyłek, zapewniając poprawną i efektywną pracę z bazą danych.