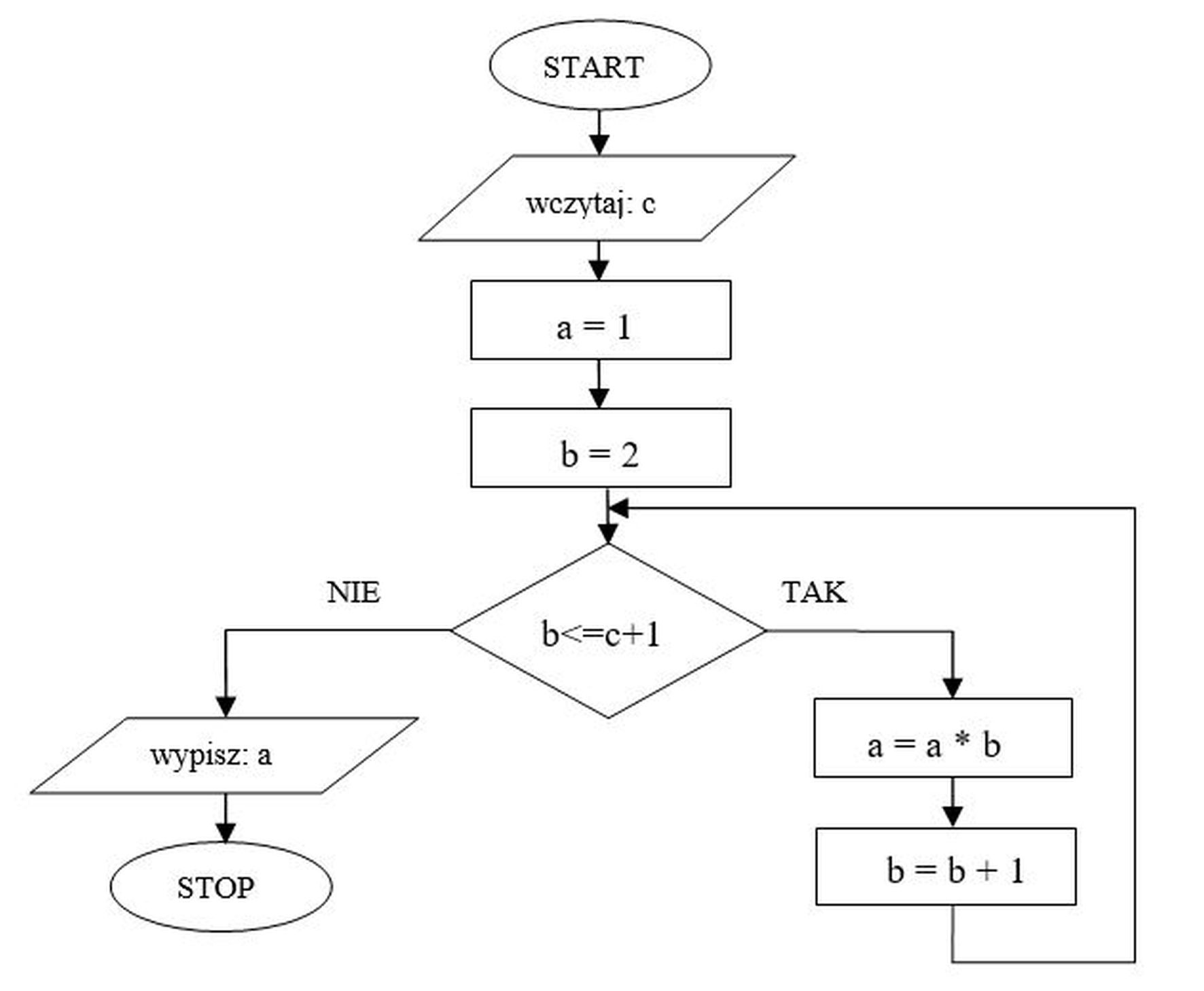
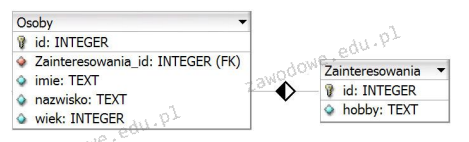
Pytanie 1
W trakcie weryfikacji stron internetowych nie uwzględnia się
A. działania hiperłączy
B. zgodności z różnymi przeglądarkami
C. błędów w składni kodu
D. źródła pochodzenia narzędzi edytorskich
Walidacja stron internetowych to proces, który ma na celu zapewnienie, że HTML, CSS oraz inne elementy technologii webowych są zgodne ze standardami określonymi przez W3C (World Wide Web Consortium). W kontekście walidacji nie bada się źródła pochodzenia narzędzi edytorskich, ponieważ te narzędzia, takie jak edytory tekstu czy IDE (Integrated Development Environment), są jedynie medium do tworzenia kodu, a nie jego treści. Z perspektywy walidacji, kluczowe jest, aby kod był syntaktycznie poprawny oraz spełniał standardy interoperability, takie jak HTML5 czy CSS3. Przykładem walidacji może być użycie narzędzi takich jak W3C Validator, które analizują kod strony i wskazują błędy składniowe, problemy z dostępnością oraz niezgodności z różnymi przeglądarkami. Dzięki walidacji, developers mogą zapewnić, że ich strony będą działały poprawnie na różnych urządzeniach i przeglądarkach, co wpływa na lepsze doświadczenia użytkowników. Walidacja jest zatem kluczowym krokiem w procesie tworzenia stron internetowych, zapewniającym ich jakość i zgodność ze światowymi standardami.