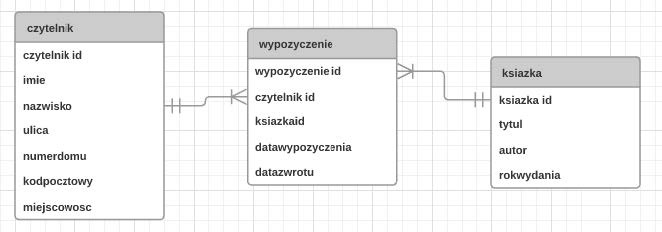
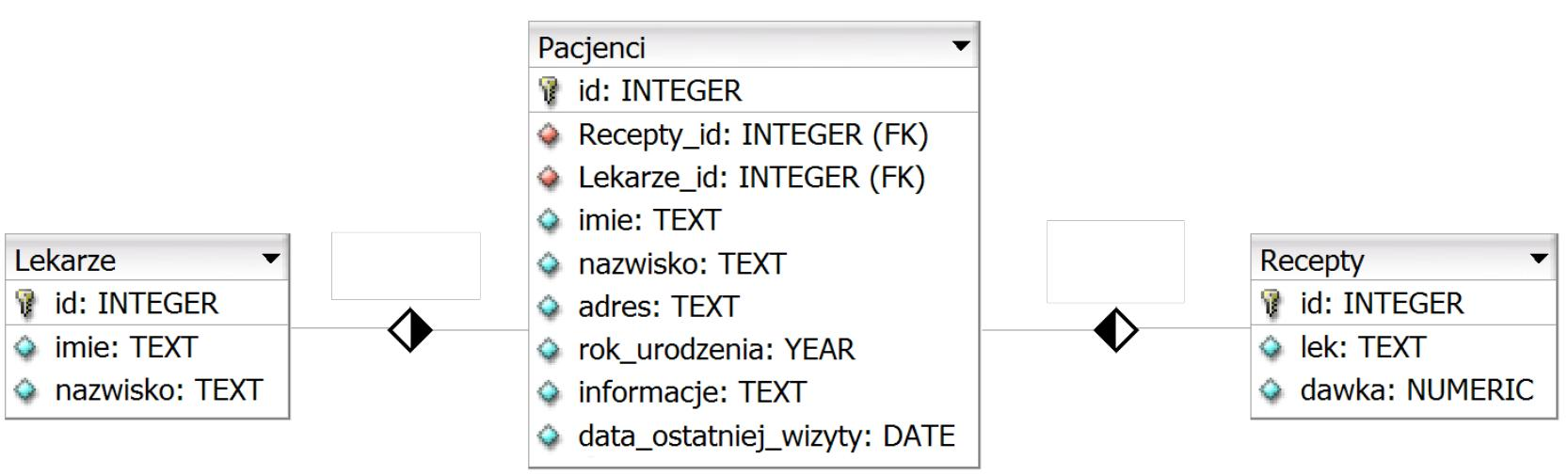
Pytanie 1
Określ rodzaj relacji między tabelami: Tabela1 oraz Tabela3?
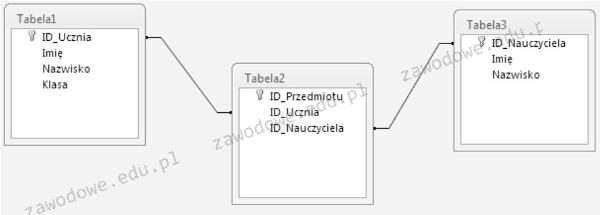
A. Jeden do wielu
B. Jeden do jednego
C. Wiele do jednego
D. Wiele do wielu
Rozważając różne typy relacji pomiędzy tabelami w relacyjnych bazach danych, istotne jest zrozumienie konceptu kluczy i połączeń. Relacja jeden do jednego implikuje, że każdemu rekordowi w jednej tabeli odpowiada dokładnie jeden rekord w drugiej. Stosuje się ją tam, gdzie dane można logicznie podzielić na dwie części, jak np. dane osobowe i szczegółowe informacje kontaktowe danej osoby. Relacja jeden do wielu oznacza, że jeden rekord z pierwszej tabeli łączy się z wieloma rekordami w drugiej. Przykładowo, jeden autor może napisać wiele książek. Taka struktura jest typowa przy modelowaniu hierarchii danych i przy relacjach typu rodzic-dziecko. W przypadku relacji wiele do wielu, potrzebna jest trzecia tabela, która pośredniczy między dwoma głównymi tabelami, przechowując ich klucze obce. Umożliwia to powiązanie wielu rekordów z obu stron. Typowe błędy polegają na niepoprawnym wyborze typu relacji, co prowadzi do redundancji danych i problemów z integralnością. Zrozumienie i prawidłowe zastosowanie tych koncepcji jest kluczowe dla projektowania efektywnych i skalowalnych baz danych, wspierając jednocześnie złożone operacje i analizy. Wybór niewłaściwego typu relacji może prowadzić do trudności w zarządzaniu danymi i skomplikowanych zapytań, co jest znanym wyzwaniem w zarządzaniu bazami danych.