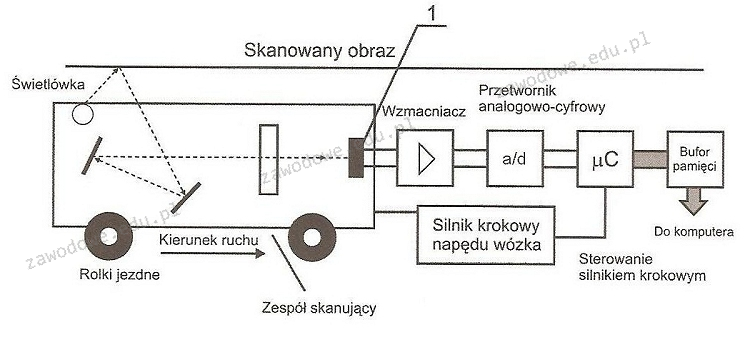
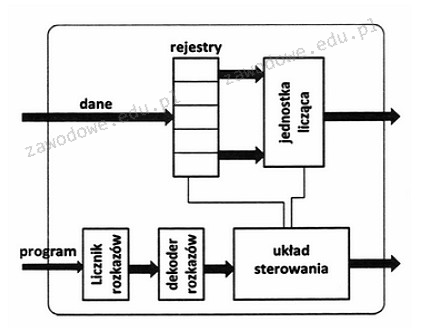
Pytanie 1
Rodzajem pamięci RAM, charakteryzującym się minimalnym zużyciem energii, jest
A. DDR3
B. DDR
C. SDR
D. DDR2
Wybór SDR, DDR, czy DDR2 nie uwzględnia istotnych różnic w architekturze i technologii, które wpływają na efektywność energetyczną pamięci. SDR (Single Data Rate) operuje na napięciu 5V i nie jest w stanie osiągnąć tych samych prędkości transferu co nowsze standardy. Oznacza to, że jest mniej wydajny i bardziej energochłonny, co czyni go nieodpowiednim rozwiązaniem w kontekście nowoczesnych wymagań dotyczących sprzętu komputerowego. DDR (Double Data Rate) działa na napięciu 2,5V, co również jest wyższe niż w przypadku DDR3 i nie zapewnia takiej samej efektywności energetycznej. DDR2 poprawił wydajność w porównaniu do DDR, ale nadal wymagał 1,8V, co jest wyższe niż napięcie robocze DDR3. Wybór starszych typów pamięci może prowadzić do nieefektywnego wykorzystania energii, co jest szczególnie istotne w przypadku urządzeń mobilnych, gdzie czas pracy na baterii jest kluczowy. Niewłaściwe podejście do wyboru pamięci operacyjnej, bazujące na przestarzałych technologiach, może negatywnie wpłynąć na wydajność systemu oraz zwiększyć koszty eksploatacji. Dlatego ważne jest, aby stosować najnowsze standardy, takie jak DDR3, które zapewniają lepszą wydajność energetyczną oraz ogólną efektywność działania.