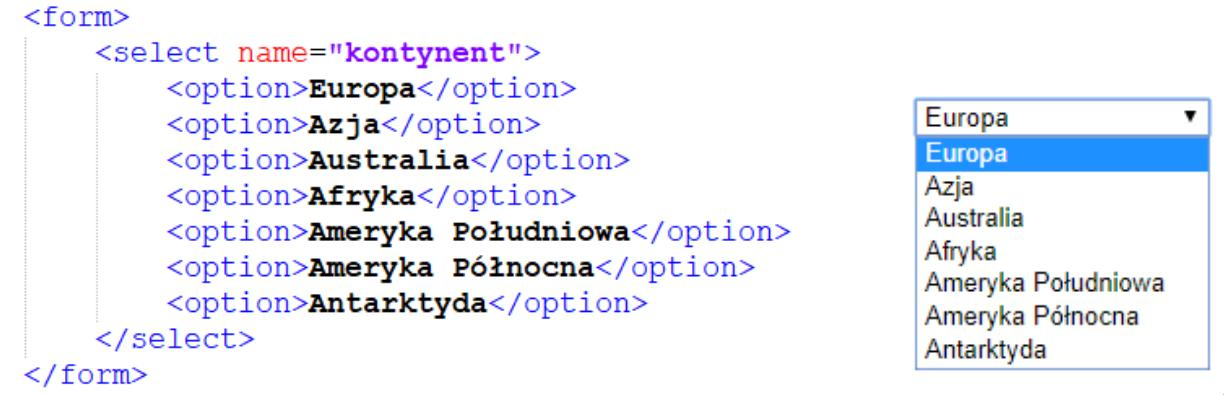
Pytanie 1
Jaką instrukcję pętli stosuje się do przeprowadzenia określonej liczby operacji na obiekcie lub zmiennej, która nie jest tablicą?
A. for
B. if
C. switch
D. foreach
Instrukcja pętli 'for' jest jednym z najczęściej używanych narzędzi programistycznych, które pozwala na wykonywanie określonej liczby operacji na zmiennej. Kluczową cechą pętli 'for' jest jej zdolność do precyzyjnego zdefiniowania liczby iteracji, co czyni ją idealną do zadań, w których liczba powtórzeń jest znana z góry. Na przykład, jeśli chcemy iterować po liczbach od 1 do 10 i wyświetlić każdą z nich, możemy użyć pętli 'for' w następujący sposób: 'for (int i = 1; i <= 10; i++) { System.out.println(i); }'. Takie podejście pozwala na łatwe zarządzanie zmiennymi oraz kontrolowanie mocy obliczeniowej programu. Pętla 'for' jest również bardzo elastyczna i może być stosowana w różnych kontekstach, takich jak przetwarzanie danych w tablicach czy lista elementów. W kontekście najlepszych praktyk, ważne jest, aby używać pętli 'for' tam, gdzie jest to najbardziej odpowiednie, unikając jej stosowania w sytuacjach, gdy mamy do czynienia z kolekcjami obiektów, które mogą wymagać bardziej zaawansowanych technik iteracyjnych. Zrozumienie zastosowania pętli 'for' jest kluczowe dla każdego programisty, który chce efektywnie zarządzać iteracjami w swoich aplikacjach.