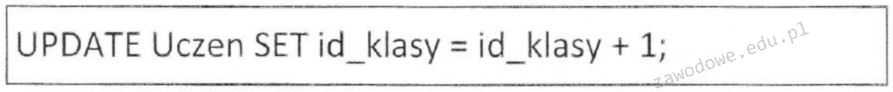Pytanie 1
Przedstawiony kod języka PHP
| $dane = array ('imie' => 'Anna', 'nazwisko' => 'Nowak', 'wiek' => 21); |
A. jest błędny, nieznany operator =>
B. definiuje tablicę z sześcioma wartościami.
C. definiuje tablicę z trzema wartościami.
D. jest błędny, indeksami tablicy mogą być tylko liczby całkowite.
Dobra robota, wybrałeś właściwą odpowiedź! Ten kod PHP, który analizujesz, rzeczywiście ustawia tablicę asocjacyjną z trzema parami klucz-wartość. Tak naprawdę tablica asocjacyjna to coś w stylu tablicy, gdzie każdemu elementowi przypisujesz unikalny klucz zamiast numeru indeksu. No i ten operator '=>' to typowy element PHP, służy do przypisywania wartości kluczom w tablicach. W twoim przykładzie widzisz, że kluczami mogą być nie tylko liczby, ale też łańcuchy tekstowe. To naprawdę przydatne, szczególnie przy przechowywaniu informacji, które łatwo zidentyfikować – na przykład numery telefonów czy adresy e-mail. Pamiętaj, że w PHP tablica to jedna z podstawowych struktur danych. Może trzymać różne typy danych, takie jak liczby, teksty, obiekty czy inne tablice, a jej rozmiar może się zmieniać w trakcie działania programu.