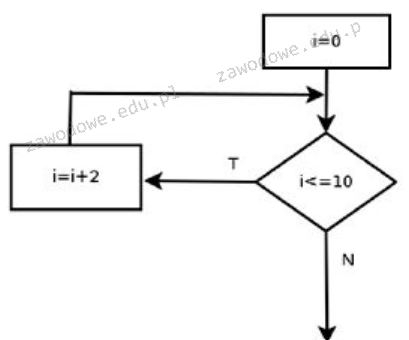
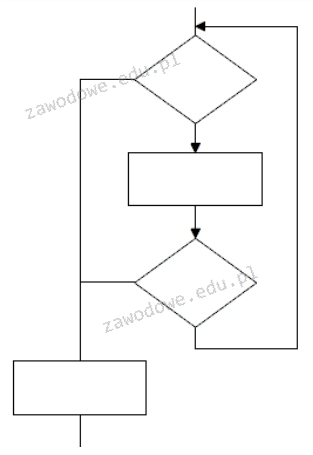
Pytanie 1
W kodzie CSS stworzono cztery klasy stylizacji, które zostały wykorzystane do formatowania akapitów. Efekt widoczny na ilustracji uzyskano dzięki zastosowaniu klasy o nazwie

A. format1
B. format4
C. format2
D. format3
Odpowiedź format2 jest poprawna, ponieważ stylizacja zastosowana do tekstu na obrazie to line-through, co oznacza przekreślenie. W CSS właściwość text-decoration pozwala na dodawanie różnych dekoracji do tekstu, takich jak underline (podkreślenie), overline (nadkreślenie) czy line-through (przekreślenie). Przekreślenie jest często używane do zaznaczania usuniętego tekstu lub do pokazywania zmian w dokumentach, co jest zgodne z dobrą praktyką w edytorach tekstu i aplikacjach do śledzenia zmian. W kodzie HTML klasy CSS są zazwyczaj stosowane poprzez dodanie atrybutu class do odpowiedniego elementu. Użycie klasy format2 w kodzie HTML wyglądałoby jak <p class='format2'>. Wielu projektantów korzysta z takich dekoracji, aby poprawić czytelność i funkcjonalność stron internetowych, zapewniając użytkownikom intuicyjne oznaczenia wizualne. Ważne jest także użycie semantycznego HTML, co w połączeniu z odpowiednimi stylami CSS pozwala tworzyć dostępne dla użytkowników strony internetowe zgodne ze standardami W3C.