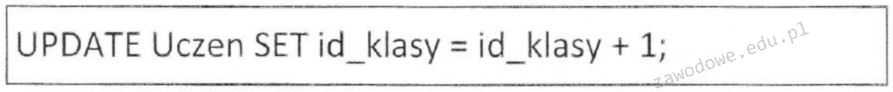Pytanie 1
Model fizyczny replikacji bazy danych pokazany na ilustracji to model
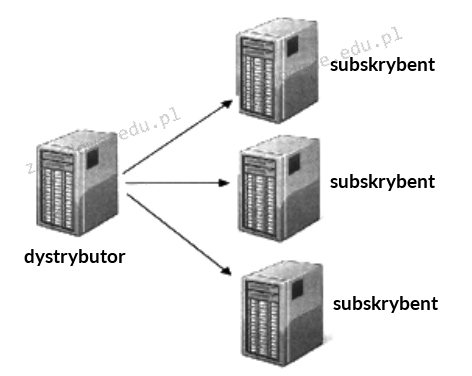
A. rozproszony
B. centralnego subskrybenta
C. centralnego wydawcy
D. równorzędny
Model centralnego wydawcy jest kluczowym elementem w systemach replikacji baz danych gdzie jeden serwer pełni rolę wydawcy dystrybutora danych do wielu subskrybentów Ta architektura pozwala na efektywne zarządzanie danymi poprzez centralne sterowanie zmianami i ich dystrybucję do podłączonych serwerów subskrybentów W praktyce takie podejście jest używane w dużych organizacjach gdzie konieczne jest zapewnienie aktualności i spójności danych w różnych lokalizacjach Przykładowo w firmach z wieloma oddziałami centralny serwer może dystrybuować dane transakcyjne do lokalnych serwerów zapewniając wszystkim oddziałom bezpośredni dostęp do aktualnych informacji Dzięki temu możliwe jest przeprowadzenie analizy danych w czasie rzeczywistym oraz synchronizacja danych co jest kluczowe w przypadku systemów ERP i CRM Stosowanie modelu centralnego wydawcy zgodnie z dobrymi praktykami umożliwia także łatwe skalowanie systemu oraz zarządzanie bezpieczeństwem danych poprzez centralne punkty kontrolne Taka architektura minimalizuje ryzyko konfliktów danych i zapewnia integralność danych co jest zgodne ze standardami branżowymi