Pytanie 1
Skrypt strony internetowej stworzony w PHP
A. jest przetwarzany na tych samych zasadach co JavaScript
B. jest realizowany po stronie klienta
C. może być uruchomiony bez wsparcia serwera WWW
D. jest realizowany po stronie serwera
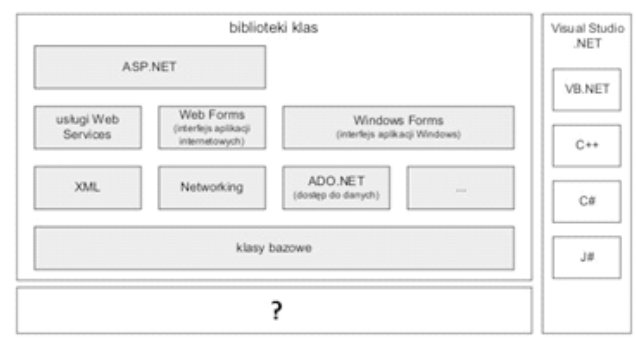
Kod strony WWW napisanej w języku PHP jest wykonywany po stronie serwera, co oznacza, że cały proces przetwarzania kodu zachodzi na serwerze, zanim strona zostanie wysłana do przeglądarki użytkownika. PHP jest językiem skryptowym, który generuje dynamiczne treści oraz może wchodzić w interakcje z bazami danych, co czyni go niezwykle efektywnym narzędziem do tworzenia aplikacji webowych. Przykładowo, gdy użytkownik wysyła formularz, skrypt PHP na serwerze może przetworzyć dane, a następnie wygenerować odpowiednią stronę HTML, która jest następnie przesyłana do klienta. Dodatkowo, PHP wspiera różne standardy, takie jak RESTful API, co pozwala na łatwe integrowanie z innymi systemami oraz aplikacjami. Warto także zauważyć, że PHP ma szeroką gamę frameworków, takich jak Laravel czy Symfony, które jeszcze bardziej ułatwiają rozwój aplikacji webowych poprzez dostarczanie gotowych rozwiązań oraz najlepszych praktyk. Z tego względu, znajomość PHP oraz jego działania po stronie serwera jest kluczowa dla każdego dewelopera webowego, który pragnie tworzyć nowoczesne i efektywne aplikacje.