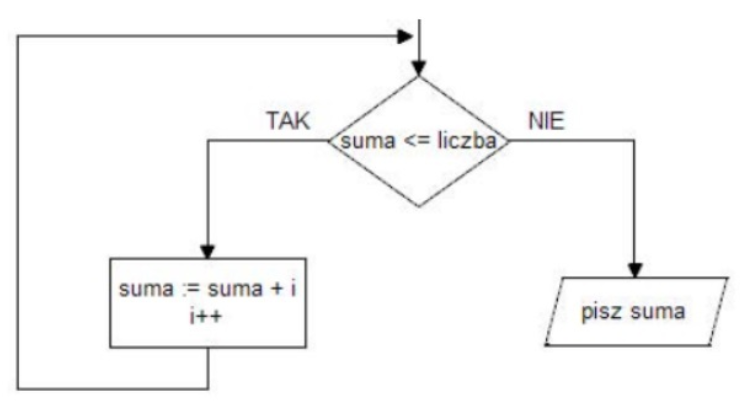
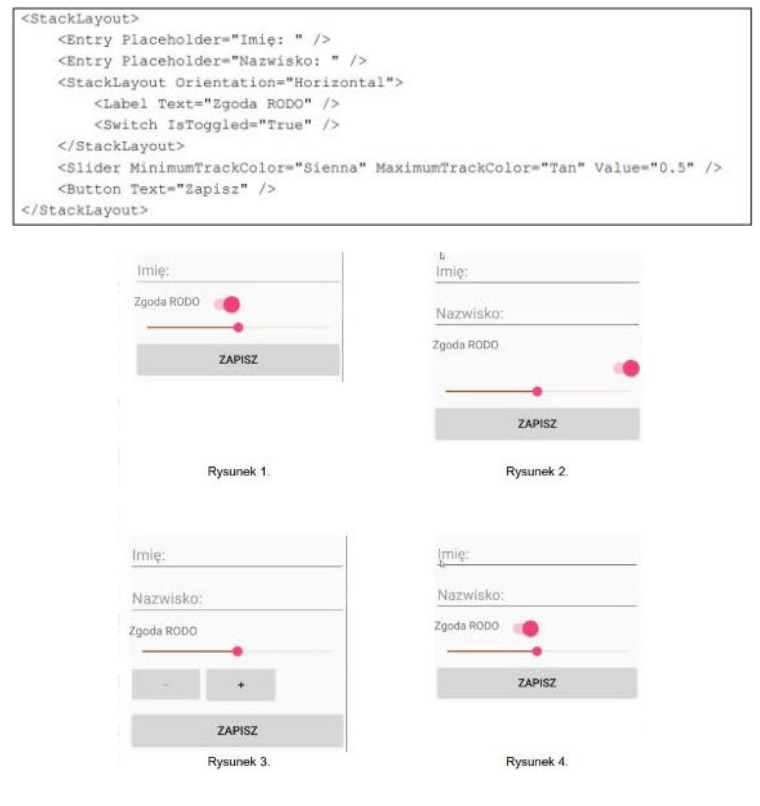
Pytanie 1
Wskaż typy numeryczne o stałej precyzji
A. long long, long double
B. bool char, string
C. float, double
D. int, short, long
Typy numeryczne o stałej precyzji (czyli tzw. typy całkowite) to na przykład int, short, long – dokładnie te, które wskazałeś. Działają one trochę jak liczniki – przechowują liczby całkowite w określonym zakresie, bez przecinka. Moim zdaniem to podstawa, jeśli chodzi o reprezentowanie wartości typu liczba sztuk, indeks, identyfikator – wszędzie tam, gdzie nie potrzebujemy części ułamkowej. Ich precyzja wynika z tego, że są zdefiniowane w standardzie (np. w C++ czy Javie) jako liczby całkowite reprezentowane przez określoną liczbę bitów. Dla przykładu, 32-bitowy int zawsze pomieści wartości od -2 147 483 648 do 2 147 483 647 i każdy bit jest tu ważny. W praktyce, programując mikrokontrolery albo systemy wbudowane, właściwy wybór typu o stałej precyzji potrafi decydować o stabilności i wydajności całego programu. Warto też wiedzieć, że typy te – int, short, long – nie mają błędu zaokrągleń, co często zdarza się przy operacjach na liczbach zmiennoprzecinkowych. No i jeszcze takie małe spostrzeżenie: dobrym zwyczajem jest wybieranie najmniejszego typu całkowitego, który pokryje wymagany zakres, żeby zoptymalizować zużycie pamięci. Takie podejście mocno się przydaje, zwłaszcza jak się pracuje nad większym projektem, gdzie każda optymalizacja jest na wagę złota.