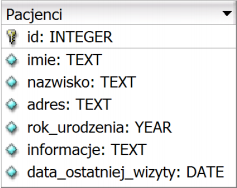
Pytanie 1
Podczas transmisji cyfrowego materiału wideo parametrem, który wpływa na jakość obrazu i dźwięku, jest bitrate. Ta wielkość określa liczbę
A. pikseli wyświetlanego obrazu wyrażoną jako stosunek jego długości do wysokości
B. próbek dźwięku w określonym czasie
C. bitów przesyłanych w określonym czasie
D. pikseli obrazu wyświetlanych na monitorze
Przepływność, czyli bitrate, to mega ważny temat, jeśli chodzi o jakość przesyłania wideo i dźwięku. Mówiąc prosto, chodzi o to, ile bitów przesyłamy w czasie. I to ma bezpośredni wpływ na to, jak wygląda obraz i jak brzmi dźwięk. Im wyższa przepływność, tym lepsza jakość, bo więcej informacji leci w jednym czasie. Na przykład, jak mamy wideo w 1080p, to przepływność na poziomie 5-10 Mbps daje całkiem dobrą jakość. A w 4K to już może być nawet 25 Mbps lub więcej. No i różne standardy, jak H.264 czy HEVC (H.265), są po to, żeby lepiej kompresować wideo – to znaczy uzyskiwać dobrą jakość przy niższej przepływności. To naprawdę ważne dla twórców i widzów, żeby mogli się cieszyć dobrym oglądaniem i słuchaniem. Przepływność mierzymy w kbps lub Mbps, co daje nam proste porównania między formatami i standardami wideo.