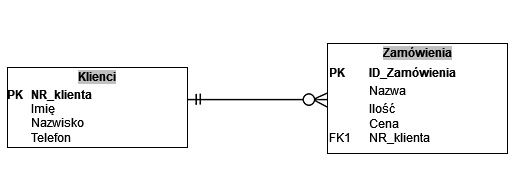
Pytanie 1
Fragment kodu SQL wskazuje, że klucz obcy

A. stanowi odniesienie do siebie samego
B. jest obecny w tabeli obiekty
C. wiąże się z kolumną imiona
D. jest ustawiony na kolumnie obiekty
W przedstawionym fragmencie kodu SQL klucz obcy (foreign key) służy do zapewnienia integralności referencyjnej między dwiema tabelami. W tym przypadku klucz obcy wskazuje, że pole imie w jednej tabeli jest powiązane z polem imiona w tabeli obiekty. Takie podejście pomaga w utrzymaniu spójności danych, ponieważ wymusza istnienie każdej wartości w polu imie w kolumnie imiona tabeli obiekty. W praktyce oznacza to, że nie można dodać wartości do pola imie, jeśli nie istnieje odpowiadająca wartość w kolumnie imiona. Klucze obce są kluczowym elementem w projektowaniu baz danych, wspierając normalizację i redukcję redundancji danych. Prawidłowe wykorzystanie kluczy obcych pozwala na efektywne zarządzanie relacjami pomiędzy danymi, co jest zgodne z najlepszymi praktykami w zakresie projektowania baz danych. Dodatkowo, prawidłowe stosowanie kluczy obcych przyczynia się do poprawy wydajności zapytań, ponieważ umożliwia optymalizację operacji łączenia danych. To podejście jest zgodne ze standardami SQL, a jego zastosowanie jest powszechne w różnych systemach zarządzania bazami danych jak MySQL, PostgreSQL czy Oracle.