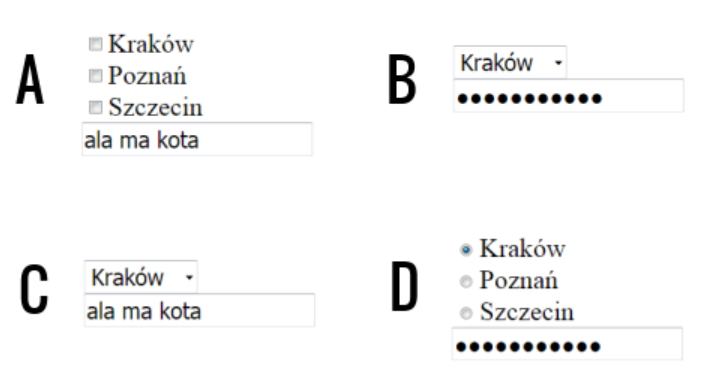
Pytanie 1
DOM oferuje metody oraz właściwości, które w języku JavaScript umożliwiają
A. pobieranie i zmianę elementów strony, która jest wyświetlana przez przeglądarkę
B. przeprowadzanie operacji na zmiennych zawierających liczby
C. manipulację łańcuchami zdefiniowanymi w kodzie
D. przesyłanie danych formularzy bezpośrednio do bazy danych
Dobra robota! Odpowiedź jest poprawna, bo to właśnie DOM, czyli Document Object Model, pozwala programistom na zmianę struktury i stylu dokumentów HTML i XML. Dzięki DOM w JavaScript można na bieżąco zmieniać treść i układ strony bez konieczności jej przeładowania. Weźmy na przykład taki przypadek: chcemy zmienić tekst w elemencie <h1>. Robimy to, wybierając ten element metodą `document.getElementById()` i przypisując nową wartość do `innerHTML`. Standardy W3C mówią, jak to wszystko ma działać, dzięki czemu DOM jest uznawany w branży. Umiejętność manipulacji DOM jest mega ważna przy tworzeniu interaktywnych aplikacji webowych, jak różne formularze, które pozwalają użytkownikom dodawać i edytować dane. Dobrze wykorzystany DOM sprawia, że aplikacje są szybsze i bardziej responsywne, co jest kluczowe w nowoczesnym programowaniu front-end.