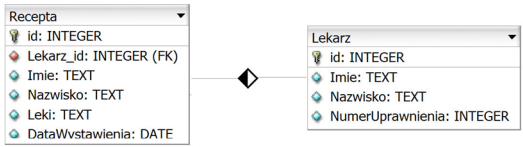
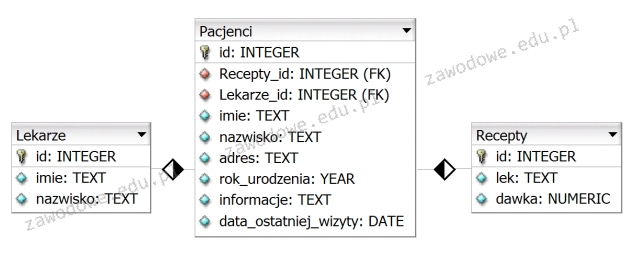
Pytanie 1
W systemie baz danych MySQL komenda CREATE USER pozwala na
A. stworzenie użytkownika oraz przypisanie mu uprawnień do bazy
B. stworzenie nowego użytkownika
C. zmianę hasła dla już istniejącego użytkownika
D. zobaczenie danych o aktualnym użytkowniku
Niemniej jednak, inne wymienione odpowiedzi nie są poprawne w kontekście polecenia CREATE USER. W szczególności, polecenie to nie służy do modyfikowania haseł istniejących użytkowników. Aby zmienić hasło dla już istniejącego konta, należy użyć polecenia ALTER USER lub SET PASSWORD, które są dedykowane do tego celu. Takie podejście pozwala na bezpieczne aktualizowanie danych uwierzytelniających bez konieczności tworzenia nowego użytkownika, a także zapewnia większą kontrolę nad polityką haseł. Kolejnym niepoprawnym stwierdzeniem jest, że CREATE USER wyświetla informacje o istniejącym użytkowniku. W rzeczywistości, aby uzyskać szczegółowe informacje o użytkownikach, należy skorzystać z zapytań SELECT na tabeli mysql.user, gdzie przechowywane są dane dotyczące kont użytkowników. Polecenie CREATE USER nie ma funkcji przeglądania ani raportowania. Ostatnia fałszywa sugestia dotyczy możliwości nadania uprawnień bezpośrednio w momencie tworzenia użytkownika. Choć polecenie CREATE USER tworzy konto, to rzeczywiste przyznawanie uprawnień jest zadaniem dla polecenia GRANT, które należy uruchomić po utworzeniu konta. Tylko poprzez oddzielne nadanie uprawnień można precyzyjnie kontrolować, jakie operacje nowy użytkownik może wykonywać na danych, co jest kluczowym elementem zarządzania bezpieczeństwem w bazach danych.