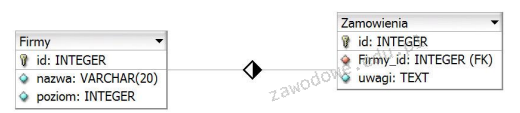
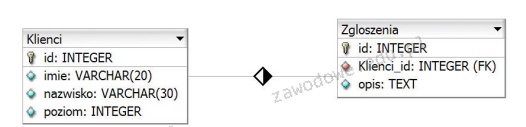
Pytanie 1
Jakie zapytanie SQL umożliwi wyszukanie z podanej tabeli tylko imion i nazwisk pacjentów, którzy przyszli na świat przed rokiem 2002?
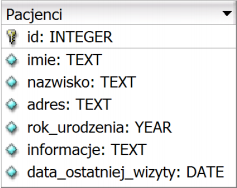
A. SELECT * FROM Pacjenci WHERE rok_urodzenia LIKE 2002
B. SELECT * FROM Pacjenci WHERE rok_urodzenia <= 2002
C. SELECT imie, nazwisko FROM Pacjenci WHERE data_ostatniej_wizyty < 2002
D. SELECT imie, nazwisko FROM Pacjenci WHERE rok_urodzenia < 2002
To zapytanie SQL, które napisałeś, czyli SELECT imie, nazwisko FROM Pacjenci WHERE rok_urodzenia < 2002, jest całkiem trafione. Po pierwsze, używasz operatora SELECT, żeby wskazać, jakie kolumny chcesz zwrócić - czyli imię i nazwisko. To jest dokładnie to, co było potrzebne. Po drugie, warunek WHERE z rokiem urodzenia zapewnia, że do wyników dostają się tylko pacjenci, którzy przyszli na świat przed 2002 rokiem. No i to jest ważne, bo masz tutaj operator mniejszości <, który wyklucza sam rok 2002. Takie podejście jest super przydatne w bazach danych, bo pozwala na filtrowanie informacji w oparciu o lata, co często wykorzystuje się w raportach i analizach. Generalnie, dobre praktyki w SQL mówią, że warto precyzyjnie określać, jakie kolumny chcesz uwzględnić, bo to pomaga odciążyć system i zrobione zapytanie będzie działać wydajniej. Twoje zapytanie nie tylko spełnia wymagania, ale także jest optymalne, co jest naprawdę istotne w pracy z bazami danych.